
软件测试的目的是为了发现软件设计和实现过程中因疏忽所造成的错误。
——《软件工程-实践者的研究方法.8th》
软件测试过程:
单元测试:侧重于以源码形式实现的每个单元(构件)。(校验详细设计)
功能测试:验证模块功能。
集成测试:侧重于软件体系结构的设计和构建。(校验概要设计)
场景测试:验证几个模块能否完成一个用户场景。
确认测试:依据已经建立的软件,对需求进行确认。
系统测试:将软件与系统的其他成分作为一个整体来测试。(校验需求分析)
验收测试(Alpha / Beta 测试):在实际用户环境中对软件进行全面的测试。
关系数据库:
第一范式(1NF, First Normal Form):数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
第二范式(2NF, Second Normal Form):数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖(部分函数依赖指的是存在组合关键字中的某些字段决定非关键字段的情况),也即所有非关键字段都完全依赖于任意一组候选关键字。
第三范式(3NF, Third Normal Form):在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合第三范式。所谓传递函数依赖,指的是如果存在"A → B → C"的决定关系,则C传递函数依赖于A。因此,满足第三范式的数据库表应该不存在如下依赖关系:关键字段 → 非关键字段x → 非关键字段y。
鲍依斯-科得范式(BCNF, Boyce-Codd Normal Form):在第三范式的基础上,数据库表中如果不存在任何字段对任一候选关键字段的传递函数依赖则符合BCNF范式。
第四范式(4NF):要求消除多值依赖。
第五范式(5NF)
第六范式(6NF)
候选字的属性是主属性,其它是非主属性。
Armstrong公理系统是由数据库专家Armstrong提出的一组定义和推理规则,形成了一个有效而完备的理论体系,用于推导关系模式中的函数依赖。
Armstrong公理包括三个基本规则,它们是自反律、增广律和传递律。这些规则可以用来推导出关系模式中所有可能的函数依赖。
自反律:如果属性集Y是属性集X的子集,那么X可以推导出Y,即X→Y。
增广律:如果X可以推导出Y,那么在X和Y中添加任何属性集Z后,XZ仍然可以推导出YZ,即XZ→YZ。
传递律:如果X可以推导出Y,且Y可以推导出Z,那么X也可以推导出Z,即X→Z。
模式(Schema)
数据库逻辑结构和特征的描述
是型(Type)的描述
反映的是数据的结构及其联系
模式是相对稳定的
实例(Instance)
模式的一个具体值(Value)
反映数据库某一时刻的状态
同一个模式可以有很多实例
实例随数据库中的数据的更新而变动
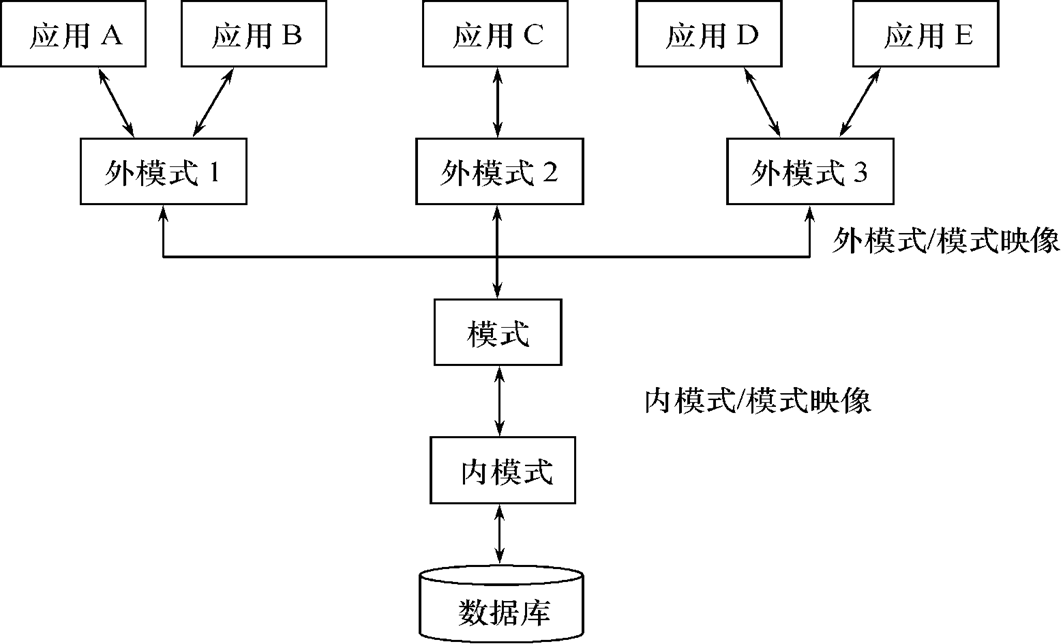
数据库的外模式(External Schema)
也称 子模式 或 用户模式
数据库用户(包括应用程序员和最终用户)使用的局部数据的逻辑结构和特征的描述
数据库用户的数据视图,是与某一应用有关的数据的逻辑表示
外模式的地位:介于模式与应用之间
模式与外模式的关系:一对多
外模式通常是模式的子集
一个数据库可以有多个外模式。反映了不同的用户的应用需求、看待数据的方式、对数据保密的要求
对模式中同一数据,在外模式中的结构、类型、长度、保密级别等都可以不同
外模式与应用的关系:一对多
同一外模式也可以为某一用户的多个应用系统所使用
但一个应用程序只能使用一个外模式
外模式的用途
保证数据库安全性的一个有力措施
每个用户只能看见和访问所对应的外模式中的数据
比如 MySQL 里的
create view class_1_students ...
数据库的模式(Schema)
也称 逻辑模式
数据库中全体数据的逻辑结构和特征的描述
所有用户的公共数据视图,综合了所有用户的需求
一个数据库只有一个模式
模式的地位:是数据库系统模式结构的中间层
与数据的物理存储细节和硬件环境无关
与具体的应用程序、开发工具及高级程序设计语言无关
模式的定义
数据的逻辑结构(数据项的名字、类型、取值范围等)
数据之间的联系
数据有关的安全性、完整性要求
比如 MySQL 里的
create table ...
数据库的内模式(Internal Schema)
也称 存储模式
是数据物理结构和存储方式的描述
是数据在数据库内部的表示方式
记录的存储方式(顺序存储,按照B+树结构存储,按hash方法存储)
比如 MySQL 里指定存储引擎:
... ENGINE = MyISAM;
索引的组织方式
数据是否压缩存储
数据是否加密
数据存储记录结构的规定
一个数据库只有一个内模式
三者的联动关系(以 MySQL 为例)
用户请求:
SELECT * FROM class_1_students外模式:验证用户权限,解析视图
class_1_students定义模式:将视图转换为底层表查询(
students和classes的JOIN)内模式:
使用 InnoDB 引擎读取
students.ibd文件通过索引
idx_student_name快速定位数据利用 B+树结构和缓冲池优化 I/O
数据独立性是由DBMS的二级映像功能来保证的。
数据的物理独立性
物理独立性意味着数据的存储方式与程序的执行过程(应用程序)相互独立。即使数据存储方式发生变化,程序的执行过程(应用程序)也不会受到影响。数据库管理员可以通过调整 模式/内模式映像 来应对存储结构的变化,而不需要修改应用程序代码。
数据的逻辑独立性
逻辑独立性指的是数据的结构和内容与程序的功能相互独立。即使模式发生变化(如增加新关系、新属性或改变属性数据类型),数据库管理员可以通过调整 外模式/模式 映像 来保持外模式不变,从而无需修改依据外模式编写的应用程序。
在关系表中选出若干属性列组成新的关系表,可以使用投影操作实现。
多处理机系统:广义上说,使用多台计算机协同工作来完成所要求的任务的计算机系统都是多处理机系统。传统的狭义多处理机系统是指利用系统内的多个CPU并行执行用户多个程序,以提高系统的吞吐量或用来进行冗余操作以提高系统的可靠性。
STD总线(Standard Data Bus):在1978年由美国PROLOG公司公布。1987年初,IEEE将STD总线定为IEEE-P961标准总线。它是一种工业标准微机控制总线,也是国内工业控制领域最常用的标准总线之一。可用于将多个处理机互连构成多处理机系统。
Crossbar(即 CrossPoint):被称为交叉开关矩阵或纵横式交换矩阵。基于总线结构的交换机一般分为共享总线和共享内存型总线两大类。最开始的以太网交换就是构建在共享总线的基础之上的。
PCI总线(Peripheral Component Interconnect Bus、外设部件互连标准总线):个人电脑中使用最为广泛的接口,几乎所有的主板产品上都带有这种插槽。PCI插槽也是主板带有最多数量的插槽类型,在流行的台式机主板上,ATX 结构的主板一般带有5~6个 PCI 插槽,而小一点的 MATX 主板也都带有2~3个 PCI 插槽,可见其应用的广泛性。虽然PCI支持多个总线主控(如多个处理机),但其集中式仲裁机制在多个主控频繁请求总线时效率低下。共享总线的物理结构进一步加剧了冲突,难以实现并行通信。
Centronics总线:接口共有36针,分为两排,8位,有点像并行口,它可以连接的设备数目最多。 它是现行PC机的主机与打印机之间最常用的接口。IEEE1284标准于1994年3月公布。IEEE1284标准具体化了操作的5种模式,每种模式都支持数据双向的传送,包括去的方向(电脑 到 peripheral),以及回的方面(peripheral 到 电脑),或是 bi-directional (一次一个方向)。

ISA(Industry Standard Architecture:工业标准体系结构):为 PC/AT 电脑而制定的总线标准,为16位体系结构,只能支持16位的 I/O 设备,数据传输率大约是 16MB/S。也称为 AT标准。其缺点是 CPU 资源占用太高,数据传输带宽太小,是已经被淘汰的插槽接口。
EISA(Extended Industry Standard Architecture:扩展工业标准结构):1989年工业厂商联盟为32位CPU设计的总线扩展标准,兼容ISA总线,现已被淘汰。
系统总线(System Bus):连接计算机主板上的主要硬件模块(CPU、内存、I/O设备等)的总线。
片内总线(On-Chip Bus):集成在单个芯片(如CPU、SoC)内部,用于连接芯片内的功能模块(如核心、缓存、外设控制器等)。
外部总线(Peripheral Bus):连接计算机主系统与外部设备(如硬盘、显卡、USB设备、网卡等)的通信通道,负责传输数据、控制信号和电源(部分总线支持供电)。
参数多态(Parametric):(通用多态)采用参数化模板,通过给出不同的类型参数,使得一个结构有多种类型。例如:C++ 的模板、Java 的泛型。
包含多态(Inclusion Polymorphism):(通用多态)通过继承或接口实现,允许子类对象以父类类型的形式被使用,并在运行时根据实际对象类型动态调用对应方法。
Animal animal = new Dog(); // Dog是Animal的子类
animal.speak(); // 运行时调用Dog的speak()方法强制多态:(特定多态)其核心是通过类型转换(隐式或显式)使得不同类型的值可以在特定上下文中被当作另一种类型处理,从而实现多态行为。它本质上是通过“强制”改变值的类型来适配操作或方法的预期类型需求。
int a = 10;
double b = a; // 隐式强制:int → double过载多态(Overloading、重载多态):(特定多态)在同一个作用域(如类)内,允许多个同名方法共存,只要它们的参数列表(参数类型、数量或顺序)不同。(静态多态)例如:C++ 的函数重载、运算符重载。
控制器:计算机控制器是计算机的神经中枢,指挥全机中各个部件自动协调工作。在控制器的控制下,计算机能够自动按照程序设定的步骤进行一系列操作,以完成特定任务。
指令寄存器(Instruction Register, IR):暂存当前正在执行的指令。
指令寄存器的位数通常与指令字长相同。
译码器:解析指令的操作码,确定需要执行的操作类型。
时序节拍发生器:产生时钟信号(Clock Signal),同步各部件操作。
操作控制部件:根据指令译码结果和时序信号,生成具体的控制信号。
程序计数器(Program Counter, PC):存储下一条待执行指令的内存地址。
在汇编语言程序中,程序员可以直接访问通用寄存器以存取数据,可以访问状态字寄存器以获取有关数据处理结果的相关信息,可以通过程序计数器进行寻址(不能直接访问,但是可以通过控制流指令间接操作,如 JMP、CALL、RET),但是不能访问指令寄存器(对程序员完全透明,IR 属于CPU流水线内部逻辑,用于指令解码,不暴露给软件层;修改IR会破坏指令执行流程,架构设计上禁止访问)。
在计算机系统中,Cache(高速缓冲存储器)与主存(主存储器)之间的地址映射是由内存管理单元(Memory Management Unit,MMU)完成的。MMU是计算机系统中的一个硬件组件,负责将逻辑地址转换为物理地址,这个过程称为地址映射。
中断向量是指中断服务程序的入口地址,通常存放在特定的内存单元中。每个中断信号对应一个中断处理程序,其入口地址被存储在中断向量中,以便在发生中断时能够快速跳转到相应的处理程序。中断向量表则是一个存放所有中断向量的表格,通常包含256个中断向量,范围为0~3FH。中断向量在计算机系统中起着至关重要的作用,帮助实现中断处理和硬件与软件的交互。
中断嵌套指中断系统正在执行一个中断服务L时,有另一个优先级更高的中断H触发,这时中断系统会暂时中止当前正在执行低优先级中断服务程序L,而去处理高级别中断H,待处理完毕,再返回被中断了的中断服务程序L继续执行。
I/O控制方式:
在微型计算机中,管理键盘最适合采用的I/O控制方式是中断驱动方式。
程序查询(轮询):CPU持续查询状态,浪费资源,不适用于低速设备。
DMA:适合高速、大批量数据传输(如磁盘),键盘的小数据量传输反而增加复杂度。
通道控制:多见于大型系统,微型计算机通常无需此类复杂架构。
DMA(Direct Memory Access)控制器是一种在系统内部转移数据的独特外设,可以将其视为一种能够通过一组专用总线将内部和外部存储器与每个具有 DMA 能力的外设连接起来的控制器。它之所以属于外设,是因为它是在处理器的编程控制下来执行传输的。
DMA控制器 的核心功能是在外设和内存之间直接传输数据。
使用 DMA 时,相当于绕过 CPU,直接与内存进行交互。
使用 DMA 传送数据时,每传送一个数据都要占用一个存储周期。
指令寻址方式
指令寻址是计算机执行程序时,CPU如何找到指令和数据的过程。不同的寻址方式影响了CPU的设计和指令集的复杂性。指令寻址方式主要分为两类:指令寻址和数据寻址。指令寻址涉及如何找到下一条待执行的指令,而数据寻址则涉及如何找到操作数的有效地址。
指令寻址
顺序寻址:CPU按顺序执行指令,通常通过程序计数器(PC)自动形成下一条指令的地址。
跳跃寻址:CPU根据当前指令提供的信息跳转到非顺序的指令地址,这通常受状态寄存器和操作数的控制。
数据寻址
立即寻址:操作数直接在指令中给出,不需要访问内存。
寄存器寻址:操作数存储在寄存器中,提供快速访问。
直接寻址:指令中给出操作数的内存地址。
寄存器间接寻址:寄存器中存储的是操作数的内存地址。
间接寻址:指令中给出的地址是操作数地址的指针,需要多次访问内存。
相对寻址:操作数地址相对于当前指令地址的偏移量计算得出。
基址寻址:操作数地址由基址寄存器和指令中的偏移量共同决定。
变址寻址:操作数地址由变址寄存器和指令中的偏移量共同决定,适用于处理数组和循环结构。
堆栈寻址:操作数存储在堆栈中,通过堆栈指针访问。
CPU调度:
放权等待(Voluntary Waiting / Yield Waiting):
进程主动触发。
进程主动释放CPU,进入阻塞状态,等待某个事件完成(如I/O操作)。
资源等待(Resource Waiting / Resource Blocking):
被动因资源不足触发。
进程因无法获取所需资源(如内存、锁、文件句柄等)而被阻塞。
定时等待(Timer Waiting / Delay Waiting):
进程主动触发。
进程主动暂停执行一段时间(如调用
sleep()),定时结束后恢复。
哈夫曼树:
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)
哈夫曼编码的一个重要特性是任何一个字符的编码都不是另一个字符编码的前缀。
哈夫曼树的每个节点要么是叶子节点,要么是度为2的节点。
海明码(Hamming Code)是一种用于错误检测和纠正的编码技术。
它的主要目的是在传输过程中检测和纠正数据中的错误。海明码的基本原理是通过在数据中添加冗余位(校验位)来创建编码,以便在出现错误时可以检测和纠正。
设数据有 n 位,校验码有 x 位。则校验码一共有 2x 种取值方式。其中需要一种取值方式表示数据正确,剩下 2x-1 种取值方式表示有一位数据出错。因为编码后的二进制串有 n+x 位,因此x应该满足
2x-1 ≥ n+x
RC5:由著名密码学家 Ronald Rivest 于1994年设计的一种对称密钥分组加密算法,以其简洁性、灵活性和高效性著称。(密钥长度可变,支持 0到2040位 的密钥,常见为128位或256位)未被广泛采纳为标准(如AES),社区支持较少。
软件可靠性:在特定环境和特定时间内,计算机程序正常运行的概率。
失效率(FIT,Failures-In-Time):一个部件每10亿机时发生多少次失效的统计测量。因此,1FIT 相当于每10亿机时发生一次失效。
平均故障间隔时间(MTBF,Mean-Time-Between-Failure,平均失效间隔时间):MTBF = MTTF + MTTR
平均故障前时间(MTTF,Mean-Time-To-Failure,平均失效时间)
平均维修时间(MTTR,Mean-Time-To-Repair)
故障率(Failure rate):在单位时间内(一般以年为单位),产品的故障总数与运行的产品总数之比叫做故障率,常用 λ 表示。
当产品的寿命服从指数分布时,故障率的倒数就是 MTBF,即 平均故障间隔时间。
例如某产品A的 MTBF 为22万小时。22万小时约为25年,并不是说A产品能工作25年不出故障。因为MTBF=1/λ ,所以可以计算出故障率 λ=1/MTBF=1/25=4%,即A产品的平均年故障率为4%,一年内,平均100台产品会有4台出故障。
可靠性:指系统在给定的时间间隔内、在给定条件下无失效运行的概率,计算公式为R=MTTF/(1+MTTF)
上下文无关文法(CFG,Context-free Grammar):编译原理中用来描述一个语言的语法结构。
A Set of Tokens or Terminal Symbols 终结符集
A Set of Non-terminals 非终结符集
A Set of Production Rules 产生式规则集
Each Rule Has the Form:NT → {T, NT}*
A Non-terminal Designated As the Start Symbol 开始符号
语法分析方法
自上而下分析法:
递归下降分析法
预测分析法
自下而上分析法:
移进-归约分析法
典型的编译流程包括:
词法分析(Lexical Analysis)
语法分析(Syntax Analysis)
语义分析(Semantic Analysis)
中间代码生成
优化
目标代码生成
语法错误是指代码的结构不符合编程语言的语法规则,例如括号不匹配、缺少分号、关键字拼写错误等。语法分析器基于语言的上下文无关文法(CFG, Context-Free Grammar)构建抽象语法树(AST)。
语义错误是指代码的语法正确,但逻辑或含义违反语言规则,例如类型不匹配、未声明的变量、函数参数错误等。语义分析器基于上下文相关的规则(如符号表、类型系统)进行检查。
MPEG-1 是 MPEG 组织制定的第一个视频和音频有损压缩标准。
MPEG-1 是为CD光盘介质定制的视频和音频压缩格式。
MPEG-1音频分三代,其中最著名的第三代协议被称为 MPEG-1 Layer 3,简称 MP3,已经成为广泛流传的音频压缩技术。MPEG-1音频技术在每一代之间,在保留相同的输出质量之外,压缩率都比上一代高。第一代协议 MP1 被应用在 LD 作为记录数字音频以及飞利浦公司的 DGC 上;而第二代协议 MP2 后来被应用于欧洲版的 DVD 音频层之一。
MPEG-1不支持间隔扫描视频,在 NTSC 视频中支持 352*240 的分辨率和 30fps 的帧率,在 PAL视频中支持 352*288 的分辨率和 25fps 的帧率。
WAV:PC机平台上很常见的、最经典的多媒体音频文件
BMP:Bitmap-File 图形文件是 Windows 采用的图形文件格式
MOV:即 QuickTime 封装格式(也叫影片格式),它是 Apple公司 开发的一种音频、视频文件封装,用于存储常用数字媒体类型。
蠕虫病毒是一种独立运行的恶意程序,它通过网络进行自我复制和传播。蠕虫病毒不需要依附在其他程序上,而是利用网络连接将自身从一个计算机系统传播到另一个计算机系统。
木马是一种伪装成合法软件的恶意程序,其目的是在用户不知情的情况下,窃取用户信息或控制用户计算机。
各种病毒:
欢乐时光(HappyTime):2001年五一前后出现,一个VB源程序病毒,专门感染 .htm、.html、.vbs、.asp 和 .htt文件。它作为电子邮件的附件,并利用 Outlook Express 的性能缺陷把自己传播出去,利用一个被人们所知的 Microsoft Outlook Express 的安全漏洞,可以在你没有运行任何附件时就运行自己。计算机用户收到带毒邮件后,不必打开信件,它就可以被激活并感染计算机,因此它的传播速度极快。“欢乐时光”病毒的发作条件是计算机时钟的日期和月份之和为13,例如5月8日或者6月7日,当染毒计算机内的时间满足上述条件时,这一病毒就会删除硬盘中的 EXE 和 DLL 文件,导致计算机系统瘫痪。
熊猫烧香:由李俊制作并肆虐网络的一款电脑病毒,一种蠕虫病毒的变种,拥有自动传播、自动感染硬盘能力和强大的破坏能力,它不但能感染系统中 exe,com,pif,src,html,asp 等文件,还能终止大量的反病毒软件进程并且会删除扩展名为 gho 的文件(该类文件是一系统备份工具“GHOST”的备份文件,删除后会使用户的系统备份文件丢失)。被感染的用户系统中所有exe可执行文件全部被改成熊猫举着三根香的模样。2006年10月16日由25岁的湖北武汉新洲区人李俊编写,2007年1月初肆虐网络,它主要通过下载的文件传染。
X卧底(Xwodi):一种能够秘密记录手机活动的监控软件。只要在对方手机里安装这款软件,安装者就可以随时随地通过电脑或手机来“监看”对方手机的所有通讯录、通话记录以及收发短信的时间内容;同时,还能随时激活被监听手机的麦克风,在机主无法察觉的情况下监听其周围的声音,如开会内容、交谈内容等。
CIH:一种能够破坏计算机系统硬件的恶性病毒。这个病毒产自中国台湾,原集嘉通讯公司(技嘉子公司)手机研发中心主任工程师陈盈豪在其于台湾大同工学院念书期间制作。最早随国际两大盗版集团贩卖的盗版光盘在欧美等地广泛传播,随后进一步通过网络传播到全世界各个角落。CIH病毒只在 windows 95、98和 windows Me 系统上发作。CIH病毒属文件型病毒,杀伤力极强。主要表现在于病毒发作后,硬盘数据全部丢失,甚至主板上BIOS中的原内容也会被彻底破坏,主机无法启动。只有更换BIOS,或是向固定在主板上的BIOS中重新写入原来版本的程序,才能解决问题。
红色代码(Code-Red):一种蠕虫病毒,能够通过网络进行传播。2001年7月13日,红色代码从网络服务器上传播开来。它是专门针对运行微软互联网信息服务软件的网络服务器来进行攻击。“红色代码”还被称为Bady,设计者蓄意进行最大程度的破坏。被它感染后,遭受攻击的主机所控制的网络站点上会显示这样的信息:“你好!欢迎光临http://wenwen.soso.com/z/UrlAlertPage.e?sp=Swww.worm.com!”。随后,病毒便会主动寻找其他易受攻击的主机进行感染。这个行为持续大约20天,之后它便对某些特定IP地址发起拒绝服务攻击。在短短不到一周的时间内,这个病毒感染了近40万台服务器,据估计多达100万台计算机受到感染。
冰河:早期的远控木马程序。冰河木马开发于1999年,在设计之初,开发者黄鑫的本意是编写一个功能强大的远程控制软件。但一经推出,就依靠其强大的功能成为了黑客们发动入侵的工具,并结束了国外木马一统天下的局面
爱虫(I LOVE YOU):又称情书或我爱你,是一个VB脚本,2000年5月3日,“我爱你”蠕虫病毒首次在香港被发现。“我爱你”蠕虫病毒病毒通过一封标题为“我爱你(ILOVEYOU)”、附件名称为“Love-Letter-For-You.TXT.vbs”的邮件进行传输。和梅利莎类似,病毒也向Outlook通讯簿中的联系人发送自身。它还大肆复制自身覆盖音乐和图片文件。它还会在受到感染的机器上搜索用户的账号和密码,并发送给病毒作者。由于当时菲律宾并无制裁编写病毒程序的法律,“我爱你”病毒的作者因此逃过一劫。
MD5 生成摘要长度:128 bit => 32(Hex-String)
SHA1 生成摘要长度:160 bit => 40(Hex-String)
SHA256 生成摘要长度:256 bit => 64(Hex-String)
RSA 密文长度 = 密钥长度
AES 始终以 128 位(16 字节)的块 为单位加密数据。无论密钥长度如何,每个明文块加密后生成的密文块大小仍为 128。总的密文长度为 128bit 的整数倍。
DES 的 块大小固定为 64 位(8 字节),与密钥长度无关。最终密文长度为 64bit 的整数倍。
冯·诺依曼机(von Neumann machine)
又称冯·诺依曼计算机,根据冯·诺依曼提出的存储程序概念设计的计算机。
基本设计思想:
存储程序
程序控制
主要特征是:
指令与数据都以二进制形式储存在存储器里(从存储器存储的内容来看两者并无区别。都是由0和1组成的代码序列,只是各自约定的含义不同而已)
指令根据其储存的顺序执行
组成:
运算器
存储器
控制器
输入设备
输出设备
软件配置管理(Software Confguration Management,SCM)也称为变更管理,是一组管理变更的活动。
软件三库管理是软件配置管理的重要组成部分,旨在确保软件开发过程中的各个阶段都能有效地管理和控制。
开发库:开发人员的工作空间,保存开发过程中需要保留的各种信息。
受控库:保存已被批准的配置项(包括基线),由配置管理员管理与维护。
产品库:最终产品的存放地,等待交付客户使用。
软件配置管理内容包括:软件配置标识、变更管理、版本控制、系统建立、配置审核和配置状态报告。
需求分析阶段完成后的文件产物:
需求规格说明(核心产物)(SRS)
可行性研究报告
项目开发计划(通常属于项目管理范畴,可能跨阶段)
系统方案建议书(解决方案的总体设计)
设计阶段完成后的文件产物:
系统设计规格说明
设计标准/设计准则(常见于设计阶段初期制定)
程序规格说明
数据库设计
编码标准(通常提前制定,可能属于预开发阶段)
用户界面标准
用户手册(初稿可能开始于设计阶段,但终稿属于交付阶段)
测试阶段完成后的产物:
验收测试计划(可能出现在设计或测试阶段)
测试标准
系统测试计划(可能在需求分析阶段就写)
系统测试数据
系统测试结果
交付/部署阶段:
操作手册
安装手册
需求跟踪:
正向跟踪。检查《产品需求规格说明书》(SRS)中的每个需求是否都能在后继工作成果中找到对应点。
逆向跟踪。检查设计文档、代码、测试用例等工作成果是否都能在《产品需求规格说明书》中找到出处。
正向跟踪和逆向跟踪合称为“双向跟踪”。不论采用何种跟踪方式,都要建立与维护需求跟踪矩阵(即表格)。需求跟踪矩阵保存了需求与后继工作成果的对应关系。
结构化分析方法中,数据流图用于功能建模,E-R图用于数据建模,状态转换图用于行为建模。
结构化分析方法的基本思想是自顶向下逐步分解。
结构化设计主要包括:
体系结构设计:定义软件的主要结构元素及其关系。
数据设计:基于实体联系图确定软件涉及的文件系统的结构及数据库的表结构。
接口设计:描述用户界面,软件和其他硬件设备、其他软件系统及使用人员的外部接口,以及各种构件之间的内部接口。
过程设计:确定软件各个组成部分内的算法及内部数据结构,并选定某种过程的表达形式来描述各种算法。
CMM(Capability Maturity Model,软件能力成熟度模型)是一种用于评价软件承包能力并帮助其改善软件质量的方法,侧重于软件开发过程的管理及工程能力的提高与评估。
以下是5个等级的基本特征:
初始级(initial):工作无序,项目进行过程中常放弃当初的计划。管理无章法,缺乏健全的管理制度。开发项目成效不稳定,项目成功主要依靠项目负责人的经验和能力,他一旦离去,工作秩序面目全非。
可重复级(Repeatable):管理制度化,建立了基本的管理制度和规程,管理工作有章可循。 初步实现标准化,开发工作比较好地按标准实施。 变更依法进行,做到基线化,稳定可跟踪,新项目的计划和管理基于过去的实践经验,具有复现以前成功项目的环境和条件。
已定义级(Defined):开发过程,包括技术工作和管理工作,均已实现标准化、文档化。建立了完善的培训制度和专家评审制度,全部技术活动和管理活动均可控制,对项目进行中的过程、岗位和职责均有共同的理解 。
已管理级(Managed):产品和过程已建立了定量的质量目标。开发活动中的生产率和质量是可量度的。已建立过程数据库。已实现项目产品和过程的控制。可预测过程和产品质量趋势,如预测偏差,及时纠正。
优化级(Optimizing):可通过采用新技术、新方法,集中精力改进过程。具备防缺陷、识别薄弱环节以及改进的手段。可取得过程有效性的统计数据,并可据此进行分析,从而得出最佳方法。
独立磁盘冗余阵列(Redundant Arrays of Independent Disks,RAID):把相同的数据存储在多个硬盘的不同的地方的方法。通过把数据放在多个硬盘上,输入输出操作能以平衡的方式交叠,改良性能。因为多个硬盘增加了平均故障间隔时间(MTBF),储存冗余数据也增加了容错。
早期 RAID 中的 I,也表示 Inexpensive,此时整个词汇表示 廉价磁盘冗余阵列。
RAID 0:无冗余的条带化模式,数据分布在多个磁盘上,读写速度最快(并行读取),但没有容错能力,适用于对速度要求高但数据安全性要求低的场合。
RAID 1:镜像模式,每个磁盘都有一个镜像盘,提供最高的数据安全性,但磁盘利用率只有 50%,适用于对数据安全性要求高的场合。
RAID 0 +1:
结合 RAID 0 和 RAID 1 的优点,既提供高性能又提供数据冗余,适用于需要高性能和高数据安全性的场合。
RAID 0+1 要在磁盘镜像中建立带区集至少 4 个硬盘。
RAID 5:
分布式奇偶校验模式,数据和奇偶校验信息分布在所有磁盘上,提供较好的读写性能和数据冗余,适用于大多数存储应用。
一种存储性能、数据安全和存储成本兼顾的存储解决方案。
RAID 5 可以理解为是 RAID 0 和 RAID 1 的折中方案。
做 RAID 5 阵列所有磁盘容量必须一样大,当容量不同时,会以最小的容量为准。 最好硬盘转速一样,否则会影响性能。
需要至少 3 块物理磁盘才能组成。
奇偶校验块的总容量 = 1块磁盘的容量(所有校验块总和占用一个磁盘的空间)
可用空间 = (磁盘数 - 1)* 最小磁盘的单盘容量
RAID 5 没有独立的奇偶校验盘,所有校验信息分散放在所有磁盘上, 只占用一个磁盘的容量。
冗余能力:允许任意1块磁盘故障而不丢失数据(通过奇偶校验恢复)。
RAID 6:双重奇偶校验模式,类似于 RAID 5,但提供更高的容错能力,适用于对数据安全性要求非常高的场合。
磁盘调度分为移臂调度和旋转调度两类,在移臂调度的算法中,先来先服务和最短寻道时间优先算法可能会随时改变移动臂的运行方向
闪存(Flash Memory)
一种非易失性存储器,即断电数据也不会丢失。
目前市面上的闪存主要有两种:NOR Flash 和 NAND Flash。
一般而言,并行接口的 Parallel Flash 是基于 NOR Flash 的;而 SSD硬盘,U盘,SD卡,eMMC 等通常是基于 NAND Flash 的。
NOR Flash 一般容量较小,随机读写的速度比较快,支持XIP(Excution In Place),但是单位容量成本较高,一般用作代码存储,比如嵌入式系统中的启动代码 U-Boot 通常存在 Parallel NOR Flash中。
NAND Flash 一般容量大,支持整页(Page)读写/编程,而且单位容量成本更低,但是随机读写速度较慢,而且不支持XIP(需要将代码拷贝到内部RAM才能可以执行),一般用来存放大容量的数据,比如手机中的视频照片等一般存在 eMMC/SD卡 中,eMMC/SD卡 中除了 NAND Flash 之外,还有一个控制管理芯片,用来进行接口协议转换,坏块管理,错误校验等。
删除(擦除)操作基于块(Block)
读取/写入(编程)的最小单位是 页(Page)
虚拟存储器(Virtual Memory):在具有层次结构存储器的计算机系统中,自动实现部分装入和部分替换功能,能从逻辑上为用户提供一个比物理存储容量大得多,可寻址的“主存储器”。虚拟存储区的容量与物理主存大小无关,而受限于计算机的地址结构和可用磁盘容量。根据所用的存储器映像算法,虚拟存储器管理方式主要有段式、页式、和段页式三种。
虚拟存储器只能基于非连续分配技术。
常见的虚拟存储器由 主存-辅存 两级存储器组成。
寄存器:放操作数、地址
CACHE:存放主存中一些经常访问的信息
主存:DRAM
盘CACHE
磁盘
磁带/其他外存
FAT 文件系统用的是 基于文件的簇状链式结构 文件管理结构。
OSI 七层网络模型(Open System Interconnection):
应用层(Application Layer):提供用户接口和应用程序之间的通信服务,用户可以访问网络应用程序,如电子邮件、文件传输和远程登录。
SSH
表示层(Presentation Layer):负责数据的格式化、加密和压缩,确保数据在不同系统之间的交换是有效的和安全的。
会话层(Session Layer):管理应用程序之间的通信会话,负责建立、维护和终止会话。
Socks
传输层(Transport Layer):为应用程序提供端到端的数据传输服务,负责数据的分段、传输控制、错误恢复和流量控制。
TCP/UDP
TCP:传输可靠的端到端字节流
SNMP使用的是无连接的UDP协议
网络层(Network Layer):负责数据包的路由和转发,以及网络中的寻址和拥塞控制。
IPSec
ICMP(Internet Control Message Protocol):一种面向无连接的协议,用于传输出错报告控制信息。
包过滤防火墙。
数据链路层(Data Link Layer):提供点对点的数据传输服务,负责将原始比特流转换为数据帧,并检测和纠正传输中出现的错误。
PPTP(Point to Point Tunneling Protocol,点对点隧道协议)
PPP 点对点协议
交换机(不涉及IP地址分配,识别的是 MAC 地址)
网桥:识别MAC地址,进行帧转发
物理层(Physical Layer):在物理媒介上传输原始比特流,定义了连接主机的硬件设备和传输媒介的规范。
中继器:对接收的信号进行再生放大,以延长传输的距离
TCP/IP 四层网络模型:
应用层
运输层
网际层
网络接口层
五层协议的体系结构:
应用层 (application layer) :
运输层 (transport layer)
网络层 (network layer)
数据链路层 (data link layer)
物理层 (physical layer)
网络层的路由协议中:
OSPF协议(Open Shortest Path First):用于网际协议(IP)网络的链路状态路由协议。该协议使用链路状态路由算法的内部网关协议(IGP),在单一自治系统(AS)内部工作。
RIP协议(Routing Information Protocol,路由信息协议):
基于距离矢量算法的路由协议,利用跳数来作为计量标准。
RIP度量的单位是跳数,其单位是1,也就是规定每一条链路的成本为1,而不考虑链路的实际带宽、时延等因素,RIP最多允许15跳。RIP利用跳数来表示它和所有已知目的地间的距离。
在带宽、配置和管理方面要求较低,主要适合于规模较小的网络中。
在IPv6地址需要通过IPv4网络进行通信时,通常采用隧道技术(Tunneling)
双栈技术(Dual Stack)是指网络设备(如路由器、服务器、终端等)同时支持IPv4和IPv6协议栈,能够直接处理两种协议的通信。
翻译技术(Translation)主要用于纯IPv6与纯IPv4网络之间的直接通信,通过协议转换实现互操作性。
网线水晶头:
平行线:网线 2头都做成 568B标准,就叫平行线。用于双机不同级连接,比如交换机连电脑。交换机连路由器。
交叉线:网线一头做成 568B,另一头做成 568A,就叫交叉线。用于双机同级连接,比如电脑连电脑,交换机连交换机。
现在都是平行线做法,设备能够自己识别。
169.254开头的IP地址是一种特殊的IP地址范围,被称为“APIPA”(Automatic Private IP Addressing)地址。当计算机无法通过DHCP(动态主机配置协议)服务器获得有效的IP地址时,会自动分配APIPA地址。这个地址的具体作用就是在你的电脑开启DHCP并且请求IP超时的时候随机生成一个 169.254.xxx.xxx 的地址用了与 广播域 中的其他设备(这个其他设备也得是169.254才行)连接的。
PPP(点对点协议)中的安全认证协议:
质询握手认证协议(Challenge Handshake Authentication Protocol,CHAP),它使用三次握手的会话过程传送密文。首先是逻辑链路建立后认证服务器就要发送一个挑战报文(随机数),终端计算该报文的Hash值并把结果返回服务器,然后认证服务器把收到的Hash值与自己计算的Hash值进行比较,如果匹配,则认证通过,连接得以建立,否则连接被终止。计算Hash值的过程有一个双方共享的密钥参与,而密钥是不通过网络传送的,所以CHAP是更安全的认证机制。在后续的通信过程中,每经过一个随机的间隔,这个认证过程都可能被重复,以缩短入侵者进行持续攻击的时间。值得注意的是,这种方法可以进行双向身份认证,终端也可以向服务器进行挑战,使得双方都能确认对方身份的合法性。
口令验证协议(Password Authentication Protocol,PAP):提供了一种简单的两次握手认证方法,由终端发送用户标识和口令字,等待服务器的应答,如果认证不成功,则终止连接。这种方法不安全,因为采用文本方式发送密码,可能会被第三方窃取。
帧中继(Frame Relay,FR)是为克服X.25交换网的缺陷、提髙传输性能而发展起来的高速分组交换技术。帧中继网络不进行差错和流量控制,并且通过流水方式进行交换,所以比X.25网络的通信开销更少,传输速度更快。
帧中继提供面向连接的虚电路服务,因而比DDN专线更能提高通信线路利用率, 用户负担的通信费用也更低廉。在帧中继网中,用户的信息速率可以在一定的范围内变化,从而既可以适应流式业务,又可以适应突发式业务,这使得帧中继成为远程传输的理想形式。
物理层是为在物理媒体上建立、维持和终止传输数据比特流的物理连接提供机械、电气、功能和规程的手段。
机械特性 指明接口所用接线器的形状和尺寸、引线数目和排列、固定和锁定装置等等。
电气特性 指明在接口电缆的各条线上出现的电压的范围。
功能特性 指明某条线上出现的某一电平的电压表示何种意义。
规程特性 指明对于不同功能的各种可能事件的出现顺序。
SMTP邮件传输协议。25端口。 应用层。
POP3邮件收取协议。110端口。 应用层。
IMAP4协议与POP3协议一样也是规定个人计算机如何访问网上的邮件的服务器进行收发邮件的协议,但是IMAP4协议同POP3协议相比更高级。
在 Java 编程语言和环境中,即时编译器(JIT compiler,just-in-time compiler)是一个把 Java 的字节码(包括需要被解释的指令的程序)转换成可以直接发送给处理器的指令的程序。
静态编译在运行程序之前就把所有的执行代码编译完,这时编译器所接受的编译信息量是不够多的。比如说:某个函数是否是大量地被调用了,函数的实参是不是一直是一个常数,等等。
编译程序生成源程序的目标程序,而解释程序则不然。解释程序也称为解释器,它或者直接解释执行源程序,或者将源程序翻译成某种中间表示形式后再加以执行;而编译程序(编译器)则首先将源程序翻译成目标语言程序, 然后在计算机上运行目标程序。这两种语言处理程序的根本区别是:在编译方式下,机器上运行的是与源程序等价的目标程序,源程序和编译程序都不再参与目标程序的执行过程;而在解释方式下,解释程序和源程序(或其某种等价表示)要参与到程序的运行过程中,运行程序的控制权在解释器。解释器翻译源程序时不产生独立的目标程序,而编译器则需将源程序翻译成独立的目标程序。
Java的栈和堆
在Java中,内存主要分为两种:栈内存和堆内存。这两种内存类型在存储数据和管理方式上有显著的区别。
栈内存
栈内存主要用于存储 基本数据类型的变量 和 对象的引用。栈内存的特点是后进先出(LIFO),即最后存入的数据最先被取出。栈内存的存取速度非常快,仅次于寄存器。
优点:
存取速度快:由于栈内存是连续的,数据的存取速度非常快。
数据共享:栈内存中的数据可以被多个线程共享。
缺点:
缺乏灵活性:栈内存的大小和数据的生存期必须在编译时确定,无法动态调整。
堆内存
堆内存用于存储由new关键字创建的对象和数组。堆内存的特点是先进先出(FIFO),即先存入的数据先被取出。堆内存可以动态分配大小,生存期不需要事先告诉编译器。
优点:
动态分配:堆内存可以在运行时动态分配,适应不同的内存需求。
存储对象和数组:堆内存专门用于存储对象和数组,适合复杂的数据结构。
缺点:
存取速度慢:由于堆内存需要在运行时动态分配,存取速度较慢。
内存管理复杂:堆内存由Java虚拟机的自动垃圾回收器管理,可能会影响性能。
栈和堆的区别
存储内容:栈内存用于存储基本数据类型的变量和对象的引用,而堆内存用于存储对象和数组
存取速度:栈内存的存取速度比堆内存快
内存管理:栈内存由系统自动管理,而堆内存由Java虚拟机的垃圾回收器管理
数据结构:栈内存是连续的,堆内存是不连续的
在彩色喷墨打印机中,将油墨进行混合后得到的颜色称为 相减色。
彩色喷墨打印机的三基色:
Cyan =青色
Magenta =洋红色,又称为“品红色”
Yellow =黄色
通常情况下,优先级 逻辑与 > 逻辑或。
逻辑表达式:
后缀表达式
中缀表达式
前缀表达式
Lisp
名称源自列表处理(LIST Processing)的英语缩写。
应用人工智能而设计的语言,是第一个声明式系内函数式程序设计语言。
Prolog
Programming in logic
一种面向演绎推理的逻辑型程序设计语言
算法设计策略
分而治之:将一个复杂的问题分解成多个小规模且结构相似的子问题来解决。这些子问题相对简单,可以递归地解决,最后将子问题的解合并得到原问题的解。分治算法的核心在于分解和合并这两个步骤。
分治算法通常包含以下三个步骤:
分解:将原问题分解成若干个小规模、相互独立且与原问题结构相似的子问题。
解决:递归地解决这些子问题。如果子问题足够小,则直接求解。
合并:将子问题的解合并成原问题的解。
贪心(Greedy Algorithm):在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,算法得到的是在某种意义上的局部最优解。例如 Dijkstra算法。
动态规划(Dynamic Programming,简称 DP):通过将原问题分解为相对简单的子问题来实现。其基本思想是利用重叠子问题和最优子结构的性质,避免重复计算,从而提高效率。
通常用于求解某种具有最优性质的问题。在这类问题中,可能会有许多可行解,每一个解都对应一个值,我们希望找到具有最优值的解。
动态规划将一个大问题化成一组互相联系、同类型的子问题。
回溯:回溯算法实际上是一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。许多复杂的,规模较大的问题都可以使用回溯法,有“通用解题方法”的美称。
回溯法采用深度优先搜索,使用堆栈存储结点,活结点的所有可行子结点被遍历后才被从栈中弹出,适用于找出满足约束条件的所有解。
分支限界:分支限界算法是一种在问题的解空间树上搜索问题解的算法,类似于回溯法,但主要用于在满足约束条件的解中找出最优解或一个可行解。它通过广度优先或最小耗费优先的策略来搜索解空间树,从而找到最优解。
分支限界法采用广度优先或最小消耗优先搜索,使用队列或优先队列存储结点,每个结点只有一次成为活结点的机会,适用于找出满足约束条件的一个解或特定意义下的最优解。
媒体的五种类型
感觉媒体(Perception Medium):直接作用于人的感觉器官,如声音和图像等。
表示媒体(Representation Medium):用于数据交换的编码,如图像编码(JPEG、MPEG)和文本编码(ASCII码)。
表现媒体(Presentation Medium):进行信息输入和输出的媒体,如键盘、鼠标、显示器等。
存储媒体(Storage Medium):用于存储表示媒体的物理介质,如硬盘、光盘等。
传输媒体(Transmission Medium):用于信息传递的媒介,如网络和电波等。
构件
系统中模块化的、可部署的和可替换的部件,该部件封装了实现并对外提供一组接口。
开闭原则(The Open-Closed Princeple, OCP):模块(构件)应该对外延具有开放性,对修改具有封闭性。
内聚性:
功能内聚:主要通过操作来体现,当一个模块完成一组且只有一组操作并返回结果时,就称此模块是功能内聚的。
分层内聚:由包、构件和类来体现。高层能够访问低层的服务,但低层不能访问高层的服务。
通信内聚:访问相同数据的所有操作被定义在一个类中。一般说来,这些类只着眼于数据的查询、访问和存储。
耦合性:
内容耦合:模块直接访问或修改另一个模块的内部数据。
共享耦合(全局耦合):模块间共享全局数据。
外部耦合:模块依赖外部系统或协议。
控制耦合:一个模块控制另一个模块的行为。
特征耦合/标记耦合(数据结构耦合):几个模块共享一个复杂的数据结构,如高级语言中的数组名、记录名、文件名等这些名字即标记,其实传递的是这个数据结构的地址
数据耦合:模块间通过参数传递数据,每一个数据都是最基本的数据。
无耦合:模块间没有直接的信息交换。
程序模块化的启发式规则:
改进软件结构提高模块独立性
模块规模应该适中
深度、宽度、扇入和扇出应适当
好的软件结构:顶层扇出较高,中层扇出较少,底层模块有高扇入
深度:表示软件结构中控制的层数,能粗略地标志一个系统的大小和复杂程度
宽度:宽度是软件结构内同一个层次上的模块总数的最大值。宽度越大系统越复杂。对宽度影响最大的因素是模块的扇出
扇出:是一个模块直接控制的模块数目
扇入:表明有多少个上级模块直接调用它。扇入越大则共享该模块的上级模块数目越多。
模块的作用域应该在控制域之内
模块的控制范围是指模块本身及其所有的下级模块的集合。
一个判定的作用范围是指所有受这个判定影响的模块。
力争降低模块接口的复杂程度
设计单入口单出口的模块
模块功能应该可以预测但要防止过分局限
类间关系可分为依赖、关联、聚合、组合和继承5种。
聚合:a part of,部分可以单独存在,并不是一定要和整体强绑定。
组合:a part of,聚合的特例,一定要和整体强绑定。
软件评审
通常把“质量”理解为“用户满意程度”,所以提高软件质量可以通过 技术评审 来达到。
使得用户满意的必要条件:
设计的规格说明书符合用户的要求,称为设计质量
程序按照设计规格说明书所规定的情况正确执行,称为程序质量
设计质量的评审内容
对象: 在需求分析阶段产生的软件需求规格说明、数据需求规格说明,及在软件概要设计阶段产生的软件概要设计说明书等
评审内容:
评价软件的规格说明是否合乎用户的要求,即总体设计思想和设计方针是否明确;需求规格说明是否得到了用户或单位上级机关的批准;需求规格说明与软件的概要设计规格说明是否一致等
评审可靠性,即是否能避免输入异常、硬件失效及软件失效所产生的失效,一旦发生应能及时采取代替手段或恢复手段
评审保密措施实现情况,即是否对系统使用资格进行检查;是否对特定数据、特定功能的使用资格进行检查;在检查出有违反使用资格的情况后,能否向系统管理人员报告有关信息;是否提供对系统内重要数据加密的功能等
评审操作特性实施情况,即操作命令和操作信息的恰当性;输入数据与输入控制语句的恰当性;输出数据的恰当性;应答时间的恰当性等
评审性能实现情况,即是否达到所规定性能的目标值
评审软件是否具有可修改性、可扩充性、可互换性和可移植性
评审软件是否具有可测试性
评审软件是否具有复用性
程序质量的评审内容
程序质量评审通常是从开发者的角度进行评审,与开发技术直接相关。
软件的结构:
功能结构,需要检查的项目如下:
数据结构(包括数据名和定义;构成该数据的数据项;数据与数据之间的关系)
功能结构(包括功能名和定义;构成该功能的子功能;功能与子功能之间的关系)
数据结构和功能结构之间的对应关系(包括数据元素与功能元素之间的对应关系;数据结构与功能结构的一致性)
功能的通用性
模块的层次
模块的结构,需要检查的项目如下:
控制流结构
数据流结构
模块结构与功能结构之间的对应关系
处理过程的结构
与运行环境的接口
检查项目如下:
与硬件的接口(包括与硬件的接口约定,即根据硬件的使用说明等所做出的规定;硬件故障时的处理和超载时的处理)
与用户的接口(包括与用户的接口约定,即输入数据的结构;输出数据的结构;异常输入时的处理,超载输入时的处理;用户存取资格的检查等)
系统可维护性的评价指标:
可理解性
可测试性
可修改性
根据ISO/IEC9126软件质量模型的定义,可维护性质量特性包含易分析性、易改变性、稳定性和易测试性4个子特性。
易分析性是指为诊断缺陷或失效原因,或为判定待修改的部分所需努力有关的软件属性;
易改变性是指与进行修改、排错或适应环境变换所需努力有关的软件属性;
稳定性是指与修改造成未预料效果的风险有关的软件属性;
易测试性是指为确认经修改软件所需努力有关的软件属性。
等价类划分:一种黑盒测试,此时每个测试用例至多覆盖一个无效等价类。
单元测试主要测试:模块接口、局部数据结构、执行路径、错误处理、边界。
面向对象软件测试
算法层:用于测试类中定义的每个方法,基本相当于传统软件测试中的单元测试。
类层:用于测试封装在同一个类中的所有方法与属性之间的相互作用。在面向对象软件中,类是基本模板,因此可认为这是面向对象测试中所特有的模块测试。
模板层:用于测试一组协同工作的类之间的相互作用。大体上相当于传统软件测试中的集成测试。但这个也有面向对象的特点,如对象之间通过发送消息相互作用。
系统层:把各个子系统组织完成的面向对象的软件系统,在组装过程中进行测试
真值:真正的数值。
原码:
符号位:使用第一位,正数为0,负数为1
例如:1(十进制真值)= 0000 0001(二进制原码)
有 +0 和 -0
正数和负数的表示范围是一样的。
反码:
正数的反码是其本身,负数的反码是在其原码的基础上符号位不变,其余各个位取反。
例如:-1(十进制真值)= 1111 1110(二进制反码)
有 +0 和 -0
正数和负数的表示范围是一样的。
补码:
正数的补码就是其本身,负数的补码是在其反码的基础上+1
例如:-1(十进制真值) = 1111 1111(二进制补码)
0(十进制真值) = 00000000(二进制补码)
定点正数表示范围:[-2n-1, 2n-1 -1 ]
定点纯小数表示范围:[-1, 1 - 2-(n-1) ]
-2n-1 = 10000...
移码:
不管正负数,只要将其补码的符号位取反即可
例如:-1(十进制真值) = 0111 1111(二进制移码)
定点正数表示范围:[-2n-1, 2n-1 -1 ]
定点纯小数表示范围:[-1, 1 - 2-(n-1) ]
在采用定点二进制的运算器中,减法运算一般是通过补码运算的二进制加法器。
定点纯小数:整数部分为0的定点小数。
定点纯小数的数据编码,仅补码/移码能够表示 -1。
若浮点数用补码表示,则判断运算结果为规格化数的方法是数符与尾数小数点后第一位数字相异为规格化数。

浮点数:
阶码:阶符 + 阶码数值部分(浮点数的小数点实际位置,影响表示范围)
尾数:数符 + 尾数数值部分
规格化正数:
原码表示:0.1xxx
补码表示:0.1xxx
规格化负数:
原码表示:1.1xxx
补码表示:1.0xxx
改编、翻译、注释、整理已有作品而产生的作品,其著作权由改编、翻译、注释、整理人享有,但行使著作权时不得侵犯原作品的著作权。
民事主体依法享有知识产权。知识产权是权利人依法就下列客体享有的专有的权利:(一)作品;(二)发明、实用新型、外观设计;(三)商标;(四)地理标志;(五)商业秘密;(六)集成电路布图设计;(七)植物新品种;(八)法律规定的其他客体。
——《民法典》
为说明某一问题,在学术论文中需要引用某些资料。必须引用已发表的作品,但只能限于介绍、评论作品。只要不构成自己作品的主要部分,可适当引用资料。不必征得原作者的同意,不需要向他支付报酬。
关于软件著作权的取得,《计算机软件保护条例》规定:“软件著作权自软件开发完成之日起产生。”即软件著作权自软件开发完成之日起自动产生,不论整体还是局部,只要具备了软件的属性即产生软件著作权,既不要求履行任何形式的登记或注册手续,也无须在复制件上加注著作权标记,也不论其是否己经发表都依法享有软件著作权。软件开发经常是一项系统工程,一个软件可能会有很多模块,而每一个模块能够独立完成某一项功能。自该模块开发完成后就产生了著作权。软件公司享有商业秘密权。因为一项商业秘密受到法律保护的依据,必须具备构成商业秘密的三个条件,即不为公众所知悉、具有实用性、采取了保密措施。商业秘密权保护软件是 以软件中是否包含着“商业秘密”为必要条件的。该软件公司组织开发的应用软件具有商业秘密的特征,即包含着他人不能知道到的技术秘密;具有实用性,能为软件公司带来经济效益;对职工进行了保密的约束,在客观上已经采取相应的保密措施。所以软件公司享有商业秘密权。商标权、专利权不能自动取得,申请人必须履行商标法、专利法规定的申请手续,向国家行政部门提交必要的申请文件,申请获准后即可取得相应权利。获准注册的商标通常称为注册商标。
著作权也称为版权。版权法是—个统称,包含各种与著作权有关的法律法规。国际上为保护计算机软件知识产权不受侵犯所采用的主要方式是实施版权法。
根据我国《计算机软件保护条例》第十七条的规定,为了学习和研究软件内含的设计思想和原理,可以通过安装、显示、传输或者存储软件等方式使用软件,而无需经过软件著作权人的许可,也无需向其支付报酬。这一条款的目的是为了促进软件技术的学习和研究,推动技术进步。
自然人的软件著作权,保护期为自然人终生及其死亡后50年,截止于自然人死亡后第50年的12月31日;软件是合作开发的,截止于最后死亡的自然人死亡后第50年的12月31日。法人或者其他组织的软件著作权,保护期为50年,截止于软件首次发表后第50年的12月31日,但软件自开发完成之日起50年内未发表的,本条例不再保护。
软件著作权属于自然人的,该自然人死亡后,在软件著作权的保护期内,软件著作权的继承人可以依照《中华人民共和国继承法》的有关规定,继承本条例第八条规定的除署名权以外的其他权利。软件著作权属于法人或者其他组织的,法人或者其他组织变更、终止后,其著作权在本条例规定的保护期内由承受其权利义务的法人或者其他组织享有;没有承受其权利义务的法人或者其他组织的,由国家享有。
DPI(Dots Per Inch,每英寸点数)是一个量度单位,表示在每英寸长度上可以打印或显示的点数,这些点可以是墨点、像素或其他形式的显示元素。
统一过程 (RUP)
RUP(Rational Unified Process)的核心特点包括迭代开发、用例驱动和以架构为中心
RUP 的软件生命周期被分解为四个阶段:初始阶段、细化阶段、构造阶段和交付阶段。
初始阶段
确定系统中大多数角色和用例。
划分主要子系统,给出系统的体系结构概貌。
分析项目的主要风险,评价项目可行性。
制定开发计划。
细化阶段(精化阶段)
进行需求、技术、技能和政策风险分析。
进行高层分析和设计,作出结构性决策。
产生简要体系结构,包括用例列表、领域概念模型和技术平台等。
构造阶段
开发并集成所有剩余的构件和应用程序功能。
详细测试所有功能。
确定产品是否可以在测试环境中进行部署。
交付阶段
确保软件对最终用户是可用的。
包括产品测试和基于用户反馈的少量调整。
确定目标是否实现,是否应该开始另一个开发周期。
PERT 网络分析法 (Program Evaluation and Review Technique) 即 “计划评估和审查技术”。简单地说,PERT 是利用网络分析制定计划以及对计划予以评价的技术。它能协调整个计划的各道工序,合理安排人力、物力、时间、资金,加速计划的完成。在现代计划的编制和分析手段上,PERT 被广泛的使用,是现代化管理的重要手段和方法。
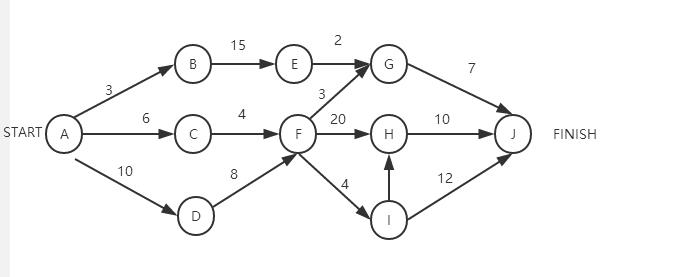
构造 PERT 图,需要明确三个概念:事件、活动和关键路线。
事件(Events)表示主要活动结束的那一点;
活动(Activities)表示从一个事件到另一个事件之间的过程;
关键路线(Critical Path)是 PERT 网络中花费时间最长的事件和活动的序列。
McCabe环路复杂度计算
McCabe环路复杂度,也称为McCabe度量法,是一种衡量程序复杂性的方法,主要基于程序的控制流。这种度量法认为程序的复杂性与程序图的复杂性密切相关,程序图是程序流程图的简化形式,其中每个处理符号都退化为一个节点,而连接不同处理符号的流线变成连接不同节点的有向弧。
环路复杂度的计算方法
环路复杂度的计算可以通过以下三种方法之一进行:
流图中的区域数等于环路复杂度。
流图G的环路复杂度 ( V(G) = E - N + 2 ),其中 ( E ) 是流图中边的条数,( N ) 是节点数。
流图G的环路复杂度 ( V(G) = P + 1 ),其中 ( P ) 是流图中判定节点的数目。
示例分析
例如,对于一个流程图,如果有 ( 10 ) 条边和 ( 8 ) 个节点,根据第二种计算方法,环路复杂度 ( V(G) ) 将是 ( 10 - 8 + 2 = 4 )。如果流程图中有 ( 2 ) 个判定节点,根据第三种计算方法,环路复杂度 ( V(G) ) 将是 ( 2 + 1 = 3 )。
在实际应用中,这种度量法常用于软件测试,特别是白盒测试,以确定测试用例的数量。例如,如果一个程序的环路复杂度为 ( 4 ),那么至少需要 ( 4 ) 个测试用例来满足路径覆盖,即覆盖程序中的所有路径。
重要考虑事项
在使用McCabe环路复杂度计算时,需要注意以下几点:
强连通分量:在计算环路复杂度时,通常假设程序的出口处有一条虚线连接回入口处,使得程序流程图成为强联通图。
程序图的绘制:需要准确地根据程序语句画出程序流程图,这是应用McCabe度量法的基础。
测试用例的设计:环路复杂度的计算结果可以指导测试用例的设计,确保测试能够全面覆盖程序的所有可能路径。
Xara 3D:专为创建最高质量的 3D 文本和图形,例如标题、徽标、标题和按钮。这是完美的方式为您的网页、邮件拍摄、影片和演示文稿添加影响(所有图像都是 完全消除锯齿,以获得流畅、专业的品质)。Xara 3D Maker 还可以 在几秒钟内创建精美的 3D 动画 - GIF、AVI 和简单的 Flash 影片 序列 - 您甚至可以通过将任何动画保存为 屏保!
Cool Edit Pro:一款数字音乐编辑器同时也是MP3制作软件,这个软件可以用声音来“绘”制:音调、歌曲的一部分、声音、弦乐、颤音、噪音或是调整静音,软件中的功能非常丰富全面,操作非常简单,这是一个非常好的软件,可以同时处理多个文件,轻松地在几个文件中进行剪切、粘贴、合并、重叠声音操作。
数据可靠性是指数据在不同时间段和来源中的一致性和准确性。它衡量数据的完整性和无误性,确保数据在使用过程中保持稳定和可信。
循环冗余校验码(CRC)利用生成多项式进行编码。设数据位为n位,校验位为k位,则CRC码的格式为n个数据位之后跟k个校验位。
软件风险
虽然对于软件风险的严格定义还存在很多争议,但一般认为软件风险包含两个特性:不确定性(uncertainty)是指风险可能发生也可能不发生,即没有100%会发生的风险;损失(loss)是指如果风险发生,就会产生恶性后果或损失。进行风险分析时,重要的是量化每个风险的不确定程度和损失程度。为了实现这一点,必须考虑不同类型的风险。
项目风险(project risk)威胁到项目计划。也就是说,如果项目风险发生,就有可能会拖延项目的进度和增加项目的成本。项目风险是指预算进度、人员(聘用职员及组织)、资源、利益相关者、需求等方面的潜在问题以及它们对软件项目的影响。项目复杂度、规模及结构不确定性也属于项目(和估算)风险因素。
技术风险(technical risk)威胁到要开发软件的质量及交付时间。如果技术风险发生,开发工作就可能变得很困难或根本不可能。技术风险是指设计、实现、接口、验证和维护等方面的潜在问题。此外,规格说明的歧义性、技术的不确定性、技术陈旧以及“前沿”技术也是技术风险因素。技术风险的发生是因为问题比我们所设想的更加难以解决。
商业风险(business risk)威胁到要开发软件的生存能力,且常常会危害到项目或产品五个主要的商业风险是:
开发了一个没有人真正需要的优良产品或系统(市场风险);
开发的产品不再符合公司的整体商业策略(策略风险);
开发了一个销售部门不知道如何去销售的产品(销售风险);
由于重点的转移或人员的变动而失去了高级管理层的支持(管理风险);
没有得到预算或人员的保证(预算风险)。
——《软件工程-实践者的研究方法.8th》
风险控制的目的是辅助项目组建立处理风险的策略。有效的策略必须考虑以下三个问题,即风险避免、风险监控和风险管理及意外事件计划,而其中风险避免是最好的风险控制策略。
风险分析在软件项目管理中具有决定性作用,风险分析实际上是贯穿软件工程的一系列风险管理步骤,其中包括风险识别、风险估计、风险管理策略、风险解决和风险监测。降低风险危害的策略包括回避风险、转移风险和接受风险并控制损失,但是不能消除风险。
在进行风险管理时,根据风险的优先级来确定风险控制策略,而优先级是根据风险暴露来确定的。风险暴露是一种量化风险影响的指标,等于风险影响乘以风险概率,风险影响是当风险发生时造成的损失。风险概率是风险发生的可能性。风险控制是风险管理的一个重要活动。
敏捷开发方法:
并列争球法(Scrum):安排多个小组并行开发,提高开发效率。同时设置一个冲刺时间段,确保任务准时完成。并列争求法使用迭代的方法,其中,把每 30天一次的迭代称为一个“冲刺”,并按需求的优先级别来实现产品。协调是通过简短的日常情况会议来进行,就像橄榄球中的“并列争球”。多个自组织和自治的小组并行地递增实现产品。
极限编程(XP):XP用“沟通、简单、反馈、勇气和尊重”来减轻开发压力和包袱。极限编程鼓励从最简单的解决方式入手再通过不断重构达到更好的结果。
水晶法(Crystal):轻量级方法论,专为小型团队量身定制。Crystal Methods背后的理念是,参与软件开发的团队通常具有不同的技能和天赋,因此Process元素不是主要因素。由于团队可以以不同的方式执行类似的任务,Crystal系列方法对此非常宽容,这使Crystal系列成为最容易应用的敏捷方法之一。
自适应软件开发(Adaptive Software Development, ASD) 是一种敏捷方法论。强调快速迭代、协作学习和持续适应变化。它适用于高度不确定、需求易变的项目,比 Scrum 更灵活,适合创新性强的产品开发。ASD 基于复杂自适应系统(CAS)理论,认为软件开发是不可预测的动态过程,需通过试错和学习逐步优化。其三大核心原则包括:使命驱动(Mission-Driven);基于特征(Feature-Based);迭代式(Iterative)。
在开发过程中,会引用第三方类。第三方类又会引用其它类。把所有要引用到的类封装在一个包中,就能提高开发效率,称为共同重用原则。
结构型设计模式描述如何将类或对象按某种布局组成更大的结构,分为类结构型和对象结构型模式。常见的结构型设计模式有:
适配器模式:将一个类的接口转换成客户希望的另一个接口。
桥接模式:将抽象部分与实现部分分离,使它们可以独立变化。
组合模式:将对象组合成树形结构以表示“部分-整体”的层次结构。
装饰器模式:动态地给对象添加额外的职责。
外观模式:为子系统中的一组接口提供一个统一的接口。
创建模式是一种设计模式,主要关注对象的创建过程,旨在将对象的创建与使用分离,从而降低系统的耦合度。创建模式包括以下几种:
单例模式:确保一个类只有一个实例,并提供一个全局访问点。它有两种实现方式:懒汉式和饿汉式。懒汉式在第一次调用时创建实例,而饿汉式在类加载时创建实例。
工厂模式:通过定义一个创建对象的接口,让子类决定实例化哪一个类。它包括简单工厂模式、工厂方法模式和抽象工厂模式。
原型模式:通过复制现有的实例来创建新的对象。它包括浅拷贝和深拷贝
建造者模式:将一个复杂对象的构造过程抽象出来,使得同样的构建过程可以创建不同的表示。
行为型模式:
策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
Apache 其默认的Web站目录为 /home/httpd。