
原文地址:www.kegel.com/c10k.html#top
翻译方式:Bing机翻(实在不靠谱)+ 人工校对纠正。
注:翻译再好,也不如看原文准确,如果强求100%完美,建议阅读原文。
注:部分计算机专门的词汇,故意没有翻译成中文,因为我觉得用英文会更准确一些(有的是真不知道要怎么翻译比较准确)。
注:原文中有些地方附带的链接(指向一些文章、网站),本文翻译时可能进行了忽略,如果有需要详细查看每个链接的内容信息,建议去原文里跳转。(有些是因为原链接过期了,有些是链接已经到不了文章原本的目标地址,所以进行了忽略)(注意有些链接需要科学上网才能访问)
注:因为译者水平有限且原文蕴含了太多专业的知识点,所以难免有些错漏。若有翻译的不妥之处,请在评论区提出。
预备知识区
注:如果下文里有些词没翻译,又看不懂,就回来这里看看。
注:如果对这几个知识点你早已滚瓜烂熟,那么大可跳过,不是必须阅读。
注:篇幅有限,这里只进行简要介绍,更多详细的细节,建议另行搜索相关资料
1、thundering herd
正文中有文章链接:www.citi.umich.edu/projects/linux-scalability/reports/accept.html
中文称为:惊群效应。
链接文章的描述:
在 Linux 中,当多个线程在同一个 TCP socket 上调用 accept() 时,它们会被置于同一个等待队列中,等待传入连接唤醒它们。在 Linux 2.2.9 内核(及更早版本)中,当接受传入的 TCP 连接时,将调用 wake_up_interruptible() 函数来唤醒等待的线程。此函数遍历 socket 的等待队列并唤醒每个线程。但是,除了一个线程之外,其他所有线程都将重新进入等待队列以等待下一个连接。这种不必要的唤醒通常被称为 “惊群效应” 问题。
2、level-triggered 和 edge-triggered
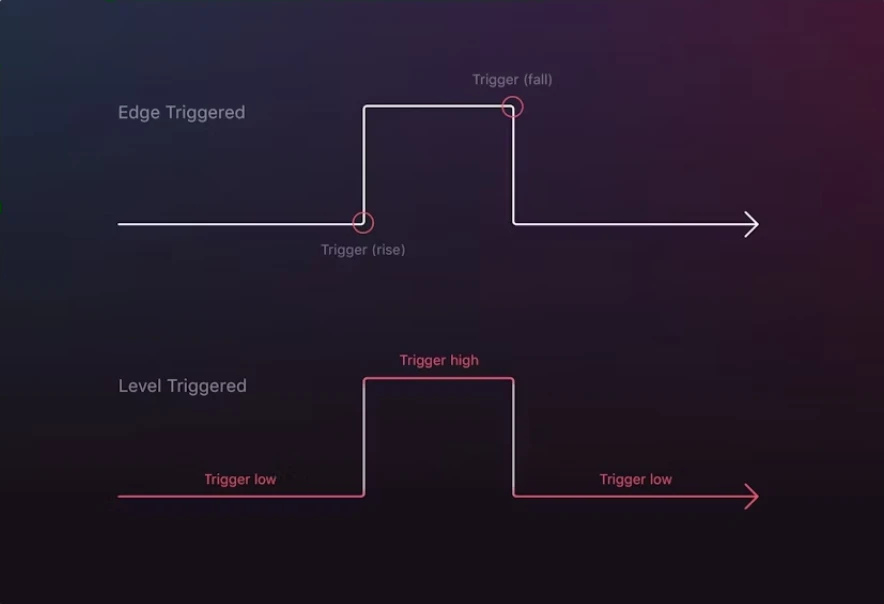 图源自:https://hackernoon.com/level-triggering-and-reconciliation-in-kubernetes-1f17fe30333d
图源自:https://hackernoon.com/level-triggering-and-reconciliation-in-kubernetes-1f17fe30333d
edge-triggered:边缘触发 或 边沿触发,有时会缩写成 ET。
即只有状态切换的时候才触发,并发出通知。
level-triggered:水平触发,有时会缩写成 LT。
即处于某个状态时,会一直在那里触发,并发出通知。
3、Green Thread(绿色线程)和 Native Thread(操作系统线程)
Green Thread 是相对于 Native Thread 的一个概念,是用户级别的线程。它由虚拟机或者运行时库模拟调度,而不是操作系统内核调度。即,对于内核来说,并不知道这些线程的存在。
而 Native Thread,是真真切切由操作系统内核管理调度。
Green Thread 不依赖操作系统调度程序,可以有自己的调度方式,即不依赖于操作系统的功能(例如平台不支持多线程,但是因为我自己实现调度,可以变相实现多线程)。但是因为不受操作系统内核管理,所以如果是多处理器平台,则享受不到操作系统内容自动将任务分配个多个处理器的优势。
实际应用中,各有各的优势场景。
Java 早期为了能在所有平台上运行,特地兼容了无 Native Thread 的操作系统,所以在虚拟机上模拟了真实内核对线程的调度。这些模拟出来的线程,就是 Green Thread。但是,在后来的版本里进行了淘汰。(按照网上的说法,似乎 Green Thread 的名称来源就是Java)
额外补充:我们常见的有进程、线程,实际还有 Fibers(纤程)、Coroutine(协程)、Goroutine。有兴趣的话,可以去多了解了解。
4、POSIX
POSIX 是可移植操作系统接口(Portable Operating System Interface) 的缩写。它是一个 IEEE 1003.1 标准,其定义了应用程序(以及命令行 Shell 和实用程序接口)和 UNIX 操作系统之间的语言接口。
当 UNIX 程序从一个 UNIX 平台移植到另一个平台时,遵守该标准可以确保其兼容性。POSIX 主要关注的是 AT&T 的 System V UNIX 和 BSD UNIX 的特性。
目的:应用程序的可移植性。
Unix上的阅读链接:https://unix.org/online.html
IEEE上的阅读链接(需要付费):https://standards.ieee.org/ieee/1003.1/7101/
5、Blocking I/O(阻塞I/O)和 Non-Blocking I/O(非阻塞I/O)
Blocking I/O(阻塞I/O):进行I/O操作时,例如还没有数据可以读/写,就会一直在那里等(阻塞在那里),直到可以进行I/O操作,然后才能执行下一步。(即强依赖这个数据的I/O,例如读取数据后,才能执行下一步操作)
Non-Blocking I/O(非阻塞I/O):进行I/O操作时,例如还没有数据可以读/写,就什么事情都不会发生,继续干下一步操作(不阻塞在那里)。
6、linux-kernel mailing list
中文翻译:Linux内核邮件列表
缩写:LKML
简介:一个专门讨论Linux内核本身的地方(可谓是Linux内核社区的核心),高手云集,它的目标就是提供尽善尽美的内核。如果你对Linux内核感兴趣,一定不能错过这里。
注意:你可以在上面发布邮件(例如报告oops问题),也可以订阅邮件(但是请先阅读下方的FAQ链接的内容)
常见问题解答(FAQ)可阅读:http://vger.kernel.org/lkml/
此外,不只是Linux,各个系统也有自己的 mailing list(邮件列表),下文中会出现好几个。不过,对于多数普通人而言,知道有这回事就行。
以下是译文
C10K问题
现在是 Web 服务器同时处理10k个客户端的时候了,你不觉得吗?毕竟网络已经很大了。
计算机现在也很强了,你可以购买一台配备 2 GB RAM 和 1000Mbit/s 以太网卡的1000MHz的机器,大约售价 1200 美元。让我们看看,现在有20K个客户端,每个客户端需要 50KHz、100KB 和 50Kbits/s。 服务器不应该需要比这更多的处理能力,即给20K个客户端里的每个客户端每秒一次从磁盘获取4KB数据并将它们发送到网络。(顺便说一句,这相当于每个客户端 0.08 美元。某些操作系统收取的 100 美元/客户端许可费现在开始看起来有点昂贵!)因此,硬件不再是瓶颈。
1999 年,最繁忙的 ftp 站点之一,cdrom.com,通过千兆以太网管道能够同时处理 10k 个客户端 。 截至 2001 年,现在有几家希望自己越来越受到大型企业客户欢迎的 ISP(1)提供了相同的能力。
(1)译者注:ISP全称Internet Service Provider,互联网服务提供商,指的是提供互联网接入服务的单位。如中国电信、中国联通等互联网运营单位及其在各地的分支机构和下属的组建局域网的专线单位。
而且,瘦客户端计算模型又回到了潮流,这次是服务器在互联网上给数以千计的客户端提供服务。
考虑到这一点,以下是一些笔记有关如何配置操作系统并编写代码来支持数千个客户端。此处的讨论内容围绕 Unix-like(类Unix)操作系统,因为这是我个人感兴趣的领域,但Windows也有涵盖一部分。
内容目录
C10K问题
相关网站
应该先阅读的书籍
I/O 框架
I/O 策略
每个线程为多个客户端提供服务,并使用非阻塞 I/O 和level-triggered(水平触发)就绪通知
传统的 select()
传统 poll()
/dev/poll(Solaris 2.7+)
kqueue(FreeBSD,NetBSD)
每个线程为多个客户端提供服务,并使用非阻塞 I/O 和更改就绪通知
epoll(Linux 2.6+)
Polyakov 的 kevent(Linux 2.6+)
Drepper 的新网络接口(针对 Linux 2.6+ 的提案)
实时信号(Linux 2.4+)
Signal-per-fd
kqueue(FreeBSD, NetBSD)
每个线程为多个客户端提供服务,并使用异步 I/O 和完成通知
每个服务器线程服务一个客户端
Linux线程(Linux 2.0+)
NGPT(Linux 2.4+)
NPTL(Linux 2.6、Red Hat 9)
FreeBSD 线程支持
NetBSD 线程支持
Solaris 线程支持
JDK 1.3.x 及更早版本中的 Java 线程支持
注意:1:1 线程 vs M:N 线程
将服务器代码构建到内核中
将 TCP 堆栈引入用户空间
评论
打开文件句柄的限制
线程限制
Java 问题 [2001 年 5 月 27 日更新]
其他技巧
Zero-Copy(零拷贝)
sendfile() 系统调用可以实现 Zero-Copy 网络
通过使用 writev(或 TCP_CORK)来避免使用小帧
一些程序可以从使用 non-Posix 线程中受益
缓存自己的数据有时是一种诀窍
其他限制
内核问题
衡量服务器性能
例子
有趣的基于 select() 的服务器
有趣的基于 /dev/poll 的服务器
有趣的基于 epoll 的服务器
有趣的基于 kqueue() 的服务器
有趣的基于实时信号的服务器
有趣的基于线程的服务器
有趣的 in-kernel 服务器
其他有趣的链接
相关网站
看看 Nick Black 大约在2009年的卓越的 Fast UNIX Servers(2) 页面情况。
2003 年 10 月,Felix von Leitner 整理了一个关于网络可扩展性的优秀网页(3)和演示稿件(4), 完成了比较各种网络系统调用和操作系统的基准测试。 他的一个观察是,Linux 2.6 内核确实击败了 2.4 内核,但是有很多很多好的图表会让操作系统开发人员思考一段时间。 (另见 Slashdot 的评论(5);看看是否有人跟进基准测试以改进 Felix 的结果将会很有趣。)
(2)Fast UNIX Servers:dank.qemfd.net/dankwiki/index.php/Network_servers 注:国内打不开,不知道是否还有效
(3)网页:bulk.fefe.de/scalability/
(4)演示稿件:bulk.fefe.de/scalable-networking.pdf
(5)Slashdot 的评论:https://developers.slashdot.org/story/03/10/19/0130256/benchmarking-the-scalability-of-bsd-and-linux
应该先阅读的书籍
如果你还没有读过它,可以出去买一本已故的 W. Richard Stevens 著的 《Unix Network Programming: Networking Apis: Sockets and Xti (Volume 1)》(6)。它描述了许多关于编写高性能服务的 I/O 策略和陷阱。 它甚至谈到了 “thundering herd(7)” 问题。 当你在做这件事时,去阅读 Jeff Darcy 关于高性能服务器设计的笔记(8)。
(另一本书可能对那些正在*使用*而不是*编写*Web服务器的人更有帮助,即 Cal Henderson的《构建可扩展的Web网站》(9)。
(6)《Unix Network Programming: Networking Apis: Sockets and Xti (Volume 1):https://www.amazon.com/exec/obidos/ASIN/013490012X/
(7)thundering herd:www.citi.umich.edu/projects/linux-scalability/reports/accept.html
(8)Jeff Darcy 关于高性能服务器设计的笔记:译者注:文章链接已不可用
(9)《构建可扩展的Web网站》:https://www.amazon.com/gp/product/0596102356
I/O 框架
可以使用预打包的库来抽象下面罗列的一些技术,将你的代码从操作系统隔离开来,使其更具可移植性。
ACE,一个重量级的 C++ I/O 框架, 包含其中一些 I/O 策略的面向对象的实现以及许多其他有用的东西。 特别是,他的 Reactor 是一种实现非阻塞 I/O 的 OO(10)方式,并且 Proactor 是一种执行异步 I/O 的 OO 方式。
(10)译者注:这里的“OO”,应该是object-oriented的缩写,即面向对象
ASIO(11) 是一个正在成为 Boost 库一部分的C++ I/O 框架。它像是 ACE 更新到了STL时代。
(11)ASIO:think-async.com/Asio/ 注:国内打不开,不知道是否还有效
libevent(12)是 Niels Provos 写的一个轻量级 C 语言 I/O 框架。它支持 kqueue 和 select, 很快将支持 poll 和 epoll。我认为它只是由 level-triggered 的, 这既有好的一面,也有坏的一面。Niels 有一个很好的关于处理一个事件消耗的时间的图(13),这个图是关于连接数量的函数。它显示 kqueue 和 sys_epoll 是明显的胜者。
(12)libevent:https://libevent.org
(13)图:https://monkey.org/~provos/libevent/libevent-benchmark.jpg
我自己对轻量级框架的尝试(遗憾的是,没有保持最新):
Poller(14) 是一种轻量级的 C++ I/O 框架,该框架实现了一个使用任何你想到的底层实现就绪 API(poll, select, /dev/poll, kqueue, or sigio)的 level-trigger 的就绪 API 。它对于比较这些 API 的性能的基准测试(15)很有用。
(14)Poller:www.kegel.com/dkftpbench/Poller_bench.html
(15)比较这些 API 的性能的基准测试:http://www.kegel.com/dkftpbench/Poller_bench.html (本文档链接指向的文档的 Poller 下方子项,以说明每个就绪 API 如何使用。)
rn(16) 是一个轻量级的 C I/O 框架,这是我在 Poller 之后的第二次尝试。它是 lgpl(17)(因此更容易在商业应用程序中使用)和 C(因此在非 C++ 应用中更容易使用)。它被用于一些商业产品。
(16)rn:http://www.kegel.com/rn/
(17)lgpl:译者注:开源许可协议的一种,官网:https://www.gnu.org/licenses/lgpl-3.0.en.html
Matt Welsh 在 2000 年 4 月写了一篇关于构建可扩展服务器时如何平衡工作线程和事件驱动技术的文章(18)。 这篇论文描述了他的 Sandstorm I/O 框架的一部分。
(18)文章:https://www.cs.berkeley.edu/~mdw/papers/events.pdf 注:资源已无
Cory Nelson's Scale! 库 - 适用于 Windows 的一个异步套接字、文件和 I/O 管道库
I/O 策略
网络软件的设计人员有很多选择。这里有几个:
是否以及如何从单个线程发出多个 I/O 调用
不这么做。通过使用阻塞/同步调用,并可能使用多个线程或进程来实现并发
使用非阻塞调用(例如,将 socket 上 write() 设置为 O_NONBLOCK )来启动 I/O, 就绪通知(例如 poll() 或 /dev/poll)用于知晓何时可以在该通道上启动下一个 I/O。 通常只能用于网络 I/O,而不能用于磁盘 I/O。
使用异步调用(例如 aio_write())启动 I/O,并使用完成通知(例如信号或完成端口) 来知晓 I/O 何时完成。适用于网络和磁盘 I/O。
如何控制为每个客户端提供服务的代码
每个客户端一个进程(经典的 Unix 方法,自 1980 年左右起使用)
一个操作系统级别的线程处理多个客户端,每个客户端由以下单位控制:
用户级线程(例如 GNU 状态线程、经典的具有 green threads 的 Java)
状态机(有点深奥,但在某些圈子里很受欢迎,我的最爱)
Continuation(有点深奥,但在某些圈子里很受欢迎)(不太确定这里指的是什么,有知道答案的读者可以解惑一下吗?)
每个客户端一个操作系统级别的线程(例如,经典的具有 native threads 的 Java)
每个活跃的客户端都有一个操作系统级别的线程(例如,使用 apache 前端的 Tomcat,NT 完成端口,线程池)
是使用标准的 O/S 服务,还是将一些代码放入内核(例如,在自定义驱动程序、内核模块或 VxD 中)
以下五种组合似乎很受欢迎:
每个线程为多个客户端提供服务,并使用非阻塞 I/O 和 level-triggered 的就绪通知
每个线程为多个客户端提供服务,并使用非阻塞 I/O 和就绪更改通知
每个服务器线程为多个客户端提供服务,并使用异步 I/O
每个服务器线程服务一个客户端,并使用阻塞 I/O
将服务代码构建到内核中
1.每个线程为多个客户端提供服务,并使用非阻塞 I/O 和 level-triggered 的就绪通知
...在所有网络句柄上设置非阻塞模式,并使用 select() 或 poll() 来判断哪个网络句柄有数据等待。 这是过去最受欢迎的执行方式。 使用此方案,内核会告诉你一个文件描述符是否已准备就绪, 无论自上次内核告诉过你这件事以后,您是否对该文件描述符执行了任何操作。(“level triggered”这个名字来自计算机硬件设计,它与“edge triggered”相反。 Jonathon Lemon 在 BSDCON 2000 关于 kqueue() 的论文(19)中介绍了这些术语。)
(19)BSDCON 2000 关于 kqueue() 的论文:https://people.freebsd.org/~jlemon/papers/kqueue.pdf
注意:记住来自内核的就绪通知只是一个提示尤其重要,因为当您尝试从中读取时,文件描述符有可能不再准备就绪。这就是为什么当使用就绪通知时使用非阻塞模式很重要。
此方法中的一个重要瓶颈是如果磁盘页不在核心中时从磁盘块 read() 或 sendfile() , 在磁盘文件句柄上设置的非阻塞模式将不起作用。 内存映射的磁盘文件也是如此。 服务第一次需要磁盘 I/O 时,其进程块、所有客户端都必须等待,原始的非线程性能就会被浪费掉。
这就是异步 I/O(AIO) 的用途,但在缺少 AIO 的系统上,执行磁盘 I/O 的工作线程或进程也可以绕过这个瓶颈。一种方法是使用内存映射文件,如果 mincore() 需要 I/O,就让一个工作线程执行 I/O, 自己则继续处理网络流量。Jef Poskanzer 提到 Pai、Druschel 和 Zwaenepoel 在 1999 年发布的 Flash Web 服务器就使用了这个技巧,他们在 Usenix '99(20)上就此发表了演讲。 看起来 mincore() 在 BSD-derived(BSD 派生)的 Unix 中可用,例如 FreeBSD 和 Solaris,但不是 Single Unix Specification(单一Unix 规范)(21)的一部分。从内核 2.3.51 开始,它作为 Linux 的一部分提供,这要归功于 Chuck Lever(22)。
(20)Usenix '99:https://www.usenix.org/legacy/events/usenix99/technical.html
(21)单一Unix 规范:https://unix.org/version4/overview.html
(22)归功于 Chuck Lever:http://www.citi.umich.edu/projects/citi-netscape/status/mar-apr2000.html
但是在 2003 年 11 月的 freebsd-hackers list 里,Vivek Pei 等人报告说,他们的 Flash Web 服务使用系统范围分析解决瓶颈问题取得了非常好的结果。他们发现的一个瓶颈是 Mincore(猜猜这并不是一个好主意),另一个事实是 sendfile 阻塞了磁盘访问。他们通过引入当提取的磁盘页尚未在核心中时返回类似 EWOULDBLOCK 的内容的修改后的 sendfile() 来提高性能。(不确定你要如何告诉用户该磁盘页现在是驻留的......在我看来,这里真正需要的是aio_sendfile() ) 他们优化的最终结果是,在 1GHZ/1GB FreeBSD 机器上,SpecWeb99 得分约为 800,这比 spec.org 存档的任何内容都要好。
有几种方法可以让单个线程判断一组非阻塞套接字中的哪一个已准备好进行 I/O:
传统的 select()
不幸的是,select() 仅限于 FD_SETSIZE 句柄。 此限制被编译到标准库和用户程序中。 (某些版本的 C 库允许在用户应用编译时提高此限制。)
有关如何将 select() 与其他就绪通知方案互换使用的示例参见 Poller_select(23) (cc, h) 。
(23)Poller_select:http://www.kegel.com/dkftpbench/doc/Poller_select.html
(?)译者注:本文中的(cc,h)均不知道是啥(原文链接都404了)
传统的 poll()
对 poll() 可以处理的文件描述符的数量并没有硬编码限制, 但它确实大约变慢了几千,因为大多数文件描述符在任何时候都处于空闲状态,并且扫描数千个文件描述符需要时间。
一些操作系统(例如 Solaris 8)通过使用 poll hinting 等技术来加速 poll() 等, 1999 年由 Niels Provos 在 Linux 上实施和进行基准测试。
有关如何将 poll() 与其他就绪通知方案互换使用的示例参见 Poller_poll(24)(cc, h, benchmarks(25)) 。
(24)Poller_poll:http://www.kegel.com/dkftpbench/doc/Poller_poll.html
(25)benchmarks:http://www.kegel.com/dkftpbench/Poller_bench.html
/dev/poll
这是 Solaris 的 poll 推荐替代。
/dev/poll 背后的想法是利用这样一个事实,即 poll() 经常被多次使用相同的参数调用。使用 /dev/poll,你可以获得 /dev/poll 的一个开放句柄,一旦你对哪些文件感兴趣,通过写入该句柄告诉操作系统。从那时起,您只需从该句柄中读取当前准备好的文件描述符集合。
它悄悄地出现在 Solaris 7 中(请参阅 patchid 106541)但它的第一次公开露面是在 Solaris 8(26) 中。据 Sun 说, 在 750 个客户端时,它只有 poll() 的 10% 开销。
(26)Solaris 8:https://docs.oracle.com/cd/E19455-01/index.html
/dev/poll 的各种实现在 Linux 上进行了尝试,但是它们的性能都不如 epoll,而且从未真正完成。不建议在 Linux 上使用 /dev/poll。
有关如何将 /dev/poll 与许多其他的就绪通知方案互换使用的示例参见 Poller_devpoll(27) (cc、h、benchmarks(28))。(注意:该示例适用于 Linux /dev/poll,可能无法在 Solaris 上正常工作。)
(27)Poller_devpoll:http://www.kegel.com/dkftpbench/doc/Poller_devpoll.html
(28)benchmarks:http://www.kegel.com/dkftpbench/Poller_bench.html
kqueue()
这是 FreeBSD(以及即将推出的 NetBSD)的 poll 推荐替代。
见下文。kqueue() 可以指定 edge triggering 或 level triggering。
2. 每个线程为多个客户端提供服务,并使用非阻塞 I/O 和就绪情况更改通知
就绪情况更改通知(或 edge-triggered 的就绪通知)意味着你给内核一个文件描述符,然后,当该描述符从未就绪过渡到就绪时,内核会以某种方式通知你。然后它假设你知道文件描述符已准备就绪,并且不会再发送该文件描述符的该类型的任何就绪通知,直到你执行某些操作导致文件描述符不再准备就绪(例如:直到你在一次发送、接收或接受调用时,收到EWOULDBLOCK 错误,或一次发送或接收转接时出现小于请求的字节数)。
使用就绪情况更改通知时,必须为虚假事件做好准备,因为一种常见的实现方式是在收到任何数据包时发出就绪信号,而不管文件描述符是否已准备就绪。
这与“level-triggered”就绪通知相反。它对编程错误的宽容度较低,因为如果你只错过了一个事件,该事件的连接就会永远卡住。尽管如此,我发现 edge-triggered 的就绪通知使使用 OpenSSL 对非阻塞客户端进行编程变得更加容易,因此值得一试。
[Banga, Mogul, Drusha '99] 在 1999 年描述了这种方案。
这里有几个允许应用程序检索“文件描述符已准备就绪”通知的 API :
kqueue()
这是 FreeBSD(以及即将推出的 NetBSD)的推荐 edge-triggered poll 替代品。
FreeBSD 4.3 和更高版本,以及 2002 年 10 月至今的 NetBSD-current,支持一个 poll() 的通用替代 kqueue()/kevent() (29)。它支持 edge-triggering 和 level-triggering。(另请参阅 Jonathan Lemon 的页面(30)和他在 BSDCon 2000 上发表的关于 kqueue() 的论文(31)。
(29)kqueue()/kevent() :https://man.freebsd.org/cgi/man.cgi?query=kqueue&apropos=0&sektion=0&manpath=FreeBSD+5.0-current&format=html
(30)Jonathan Lemon 的页面:https://people.freebsd.org/~jlemon/
(31)论文:https://people.freebsd.org/~jlemon/papers/kqueue.pdf
与 /dev/poll 一样,你分配了一个监听对象,但不是打开文件 /dev/poll,而是调用 kqueue() 来分配一个。要更改正在侦听的事件,或获取当前事件的列表,请在 kqueue() 返回的描述符上调用 kevent() 。它不仅可以侦听 socket 就绪情况,还可以侦听普通文件就绪情况、信号,甚至还有 I/O 完成情况。
注意:截至 2000 年 10 月,FreeBSD 上的线程库仍不能很好地与 kqueue() 交互。显然,当 kqueue() 阻塞时,整个进程都会阻塞,而不仅仅是调用线程。
有关如何将 kqueue() 与许多其他就绪通知方案互换使用的示例,请参见 Poller_kqueue(32)(cc、h、benchmarks)。
(32)Poller_kqueue:http://www.kegel.com/dkftpbench/doc/Poller_kqueue.html
使用 kqueue() 的示例和库:
PyKQueue(33) -- kqueue() 的 Python 调用
(33)PyKQueue:https://people.freebsd.org/~dwhite/PyKQueue/
Ronald F. Guilmette 的 echo 服务器示例(34),另请参阅他在 2000 年 9 月 28 日发表在 freebsd.questions 上的帖子(35)。
(34)echo 服务器示例:http://www.monkeys.com/kqueue/echo.c
(35)帖子:http://groups.yahoo.com/group/freebsd-questions/message/223580 注:国内打不开,不知道是否还有效
epoll
这是 2.6 Linux 内核的 edge-triggered poll 推荐 替代。
2001年7月11日,Davide Libenzi 提出了实时信号的替代方法。他的补丁提供了他现在称之为 /dev/epoll(36)的东西。这就像实时信号就绪通知一样,但它合并了冗余事件,并具有更有效的批量事件检索方案。
(36)/dev/epoll:www.xmailserver.org/linux-patches/nio-improve.html 注:国内打不开,不知道是否还有效
Epoll 在 2.5.46 的接口从 /dev 中的特殊文件更改为系统调用 sys_epoll 后,被合并到 2.5 内核树中。旧版本 epoll 的补丁可用于 2.4 内核。
在 2002 年万圣节前后,关于在 linux-kernel mailing list 上统一 epoll、aio 和其他事件源,存在着长时间的争论。它可能还会发生,但 Davide 首先专注于巩固 epoll。
Polyakov's kevent (Linux 2.6+)
新闻快讯:2006 年 2 月 9 日和 2006 年 7 月 9 日,vgeniy Polyakov 发布了似乎统一了 epoll 和 aio 的补丁,他的目标是支持网络 AIO。参见:
关于 kevent 的 LWN 文章(https://lwn.net/Articles/172844/)
他在 7 月的声明(https://lkml.org/lkml/2006/7/9/82)
他的 Kevent 页面(译者注:网站凉了)
他的 Naio 页面 (译者注:网站凉了)
最近的一些讨论(http://thread.gmane.org/gmane.linux.network/37595/focus=37673 注:国内打不开,不知道是否还有效)
Drepper 的新网络接口(针对 Linux 2.6+ 的提案)
在 OLS 2006 上,Ulrich Drepper 提出了一种新的高速异步网络 API。参见:
他的论文:“异步、零拷贝网络 I/O 的需求"(https://www.akkadia.org/drepper/newni.pdf)
7月22日的LWN文章 (https://lwn.net/Articles/192410/)
实时信号
这是 2.4 Linux 内核的 edge-triggered poll 推荐替代。
2.4 linux 内核可以通过特定的实时信号传递 socket 就绪事件。以下是如何打开此行为:
/* Mask off SIGIO and the signal you want to use. */
sigemptyset(&sigset);
sigaddset(&sigset, signum);
sigaddset(&sigset, SIGIO);
sigprocmask(SIG_BLOCK, &m_sigset, NULL);
/* For each file descriptor, invoke F_SETOWN, F_SETSIG, and set O_ASYNC. */
fcntl(fd, F_SETOWN, (int) getpid());
fcntl(fd, F_SETSIG, signum);
flags = fcntl(fd, F_GETFL);
flags |= O_NONBLOCK|O_ASYNC;
fcntl(fd, F_SETFL, flags);
当 read() 或 write() 等正常 I/O 函数完成时,将会发送信号。要使用它,需要编写一个常规的 poll() 外部循环。在循环内,通过 poll() 处理完所有文件描述符的通知后,循环调用 sigwaitinfo() (37)。
(37)sigwaitinfo() :http://www.opengroup.org/onlinepubs/007908799/xsh/sigwaitinfo.html 注:国内打不开,不知道是否还有效
如果 sigwaitinfo 或 sigtimedwait 返回你的实时信号,siginfo.si_fd 和 siginfo.si_band 在调用 poll() 后提供与 pollfd.fd 和 pollfd.revents 几乎相同的信息,因此你处理 I/O,并继续调用 sigwaitinfo() 。
如果 sigwaitinfo 返回一个传统的 SIGIO,则信号队列溢出, 因此,您可以通过暂时将信号处理器更改为 SIG_DFL 来刷新信号队列, 并退出外部 poll() 循环。
有关如何将实时信号与许多其他就绪通知方案互换使用的示例,请参阅 Poller_sigio(38) (cc, h)。
(38)Poller_sigio:http://www.kegel.com/dkftpbench/doc/Poller_sigio.html
请参阅 Zach Brown 的 phhttpd,了解直接使用此功能的示例代码。(或者不,phhttpd 有点难以弄清楚......)
[Provos,Lever,and Tweedie 2000](39) 描述了 phhttpd 的最新基准测试,它使用 sigtimedwait() 的变种 sigtimedwait4() ,它允许你通过一次调用检索多个信号。有趣的是,sigtimedwait4() 对他们来说的主要好处似乎是它允许应用程序度量系统过载(因此它可以适当地运行)。(请注意,poll() 提供了相同的系统过载度量能力)
(39)[Provos,Lever,and Tweedie 2000]报告下载链接:http://www.citi.umich.edu/techreports/reports/citi-tr-00-7.ps.gz
Signal-per-fd
Chandra 和 Mosberger 提出了一种对实时信号方法的修改,称为 “signal-per-fd”,它通过合并冗余事件来减少或消除实时信号队列溢出。不过,它的表现并不优于 epoll。他们的论文(www.hpl.hp.com/techreports/2000/HPL-2000-174.html)将该方案的性能与select() 和 /dev/poll 进行了比较。
Vitaly Luban 于2001年5月18日宣布了实现这一方案的补丁,他的补丁位于 www.luban.org/GPL/gpl.html。(注意:截至 2001 年 9 月,此修补程序在高负载下可能仍存在稳定性问题。dkftpbench(40) 在大约 4500 个用户时可能会触发 OOPS。)
(40)dkftpbench:http://www.kegel.com/dkftpbench/
(?)oops:译者注:原意是一个拟声词,类似中文里的“哎呦”。在内核开发里代表内核出错(类似内核跟你说“哎呦,不好意思,我搞砸了”),此时内核会打印oops信息,比如寄存器状态、堆栈信息等,帮助开发者定位问题。(参考自文章:https://blog.csdn.net/gy794627991/article/details/126650460)
有关如何将 signal-per-fd 与许多其他就绪通知方案互换使用的示例,请参阅 Poller_sigfd(41)(cc, h)。
(41)Poller_sigfd:http://www.kegel.com/dkftpbench/doc/Poller_sigfd.html
3. 每个服务器线程为多个客户端提供服务,并使用异步 I/O
这在 Unix 中还没有流行起来,可能是因为很少有操作系统支持异步 I/O,也可能是因为它(如非阻塞 I/O)需要重新思考你的应用程序。在标准 Unix 下,异步 I/O 由 aio_interface(42) 提供,该接口将信号和值与每个 I/O 操作相关联。信号及其值被排队并有效地传送到用户进程。这是来自 POSIX 1003.1b 实时扩展,也位于 Single Unix 规范 V2 版本中。
(42)aio_interface:http://www.opengroup.org/onlinepubs/007908799/xsh/realtime.html(从该链接向下滚动到“异步输入和输出”) 注:国内打不开,不知道是否还有效
AIO 通常与 edge-triggered 的完成通知一起使用,即在操作完成时将信号排队。(它也可以通过调用 aio_suspend()(43) 与 level triggered 的完成通知一起使用,尽管我怀疑很少有人这样做。
(43)aio_suspend():http://www.opengroup.org/onlinepubs/007908799/xsh/aio_suspend.html 注:国内打不开,不知道是否还有效
glibc 2.1 及更高版本提供了为符合标准而非性能来编写的通用实现。
Ben LaHaise 的 Linux AIO 实现已合并到自 2.5.32 起的 Linux 内核主干中。它不使用内核线程,并且具有非常高效的底层 API,但(截至 2.6.0-test2)尚不支持socket。(2.4 内核也有一个 AIO 补丁,但 2.5/2.6 的实现略有不同。更多信息:
“Linux内核的异步I/O(AIO)支持(44)”页面试图将有关 2.6 内核实现 AIO 的所有信息联系在一起(发布于 2003 年 9 月 16 日)
(44)Linux内核的AIO支持:https://lse.sourceforge.net/io/aio.html
《第3轮: aio vs /dev/epoll》,作者Benjamin C.R. LaHaise (在2002的 OLS 上发表)(http://www.linuxsymposium.org/2002/view_txt.php?text=abstract&talk=11 注:链接打不开)
《Linux 2.5 中的异步 I/O 支持》,作者:Bhattacharya、Pratt、Pulaverty 和 Morgan,IBM。在2003年 OLS 上发表。(http://archive.linuxsymposium.org/ols2003/Proceedings/All-Reprints/Reprint-Pulavarty-OLS2003.pdf 注:链接打不开)
《Linux 异步 I/O (aio) 设计说明》,作者:Suparna Bhattacharya -- 将 Ben 的 AIO 与 SGI 的 KAIO 和其他一些 AIO 项目进行比较。(http://sourceforge.net/docman/display_doc.php?docid=12548&group_id=8875 注:链接打不开)
Linux AIO 主页(注:链接凉了):Ben 的初步补丁、邮件列表等。
Linux-AIO mailing list 存档(http://marc.theaimsgroup.com/?l=linux-aio 注:链接打开一片空白)
libaio-oracle:在 libaio 之上实现标准 Posix AIO 的库。Joel Becker 于 2003 年 4 月 18 日首次提及(http://marc.theaimsgroup.com/?l=linux-aio&m=105069158425822&w=2 注:链接打开一片空白)。
libaio-oracle:http://www.ocfs.org/aio/ 注:链接打不开
Suparna 还建议查看 DAFS API 的 AIO 方法(45)。
(45)DAFS API 的 AIO 方法:https://www.dafscollaborative.org/tools/dafs_api.pdf
Red Hat AS 和 Suse SLES 都在 2.4 内核上提供了高性能的实现;它与 2.6 内核实现相关,但不完全相同。
2006年2月,提供网络AIO的实践正在进行一个新的尝试。请参阅上面关于Evgeniy Polyakov 基于 kevent 的 AIO 的新闻快讯。
1999 年,SGI 在 Linux 上实施了高速 AIO。从 V1.1 开始,据说它在磁盘 I/O 和 socket 上工作良好。它似乎使用的是内核线程。不过对于那些等不及 Ben 的 AIO 支持 socket 的人来说,它仍然很有用。
O'Reilly的著作《POSIX.4:Programming for the Real World》(46)据说包括了对aio有一个很好的介绍。
(46)《POSIX.4:Programming for the Real World》:《POSIX:真实世界编程》,真实世界的编程(通常称为实时编程)是以某种方式与日常生活的“现实世界”交互的编程。
有关在 Solaris 上非标准 aio 实现的早期教程,请在线访问 Sunsite。它很可能值得一看,但请记住,你需要在脑海里将 “aioread” 转换为 “aio_read” 等。
请注意,AIO 不提供在不阻塞磁盘 I/O 的情况下打开文件的途径。如果你担心打开磁盘文件导致的 sleep,Linus 建议你应该简单地在不同的线程中执行 open() ,而不是指望 aio_open() 系统调用。
在 Windows 下,异步 I/O 与术语 “Overlapped I/O(重叠I/O)” 和 IOCP 或 “I/O Completion Port(I/O完成端口)” 相关联。Microsoft 的 IOCP 将先前的技术如异步 I/O(如 aio_write)和 排队完成通知(如将 aio_sigevent 字段与 aio_write 一起使用时)与保留某些请求的新想法相结合,以尝试保持与单个 IOCP 关联的正在运行的线程数不变。有关更多信息,请参见 sysinternals.com 上 Mark Russinovich 撰写的 Inside I/O Completion Ports、Jeffrey Richter 的著作《Programming Server-Side Applications for Microsoft Windows 2000》(Amazon(47),MSPress)、美国专利 #06223207(48) 或 MSDN。
(47)Amazon购买链接:https://www.amazon.com/exec/obidos/ASIN/0735607532
(48)美国专利 #06223207:http://patft.uspto.gov/netacgi/nph-Parser?Sect1=PTO1&Sect2=HITOFF&d=PALL&p=1&u=/netahtml/srchnum.htm&r=1&f=G&l=50&s1=%276223207%27.WKU.&OS=PN/6223207&RS=PN/6223207 注:国内打不开,不知道是否还有效
4. 为每个服务器线程服务一个客户端
...并让 read() 和 write() 块。缺点是每个客户端使用整个堆栈帧,这会消耗内存。许多操作系统在处理几百个以上的线程时也会遇到麻烦。如果每个线程都获得一个 2MB 的堆栈(这不是一个罕见的默认值),则在具有 1GB 用户可访问虚拟内存的 32 位计算机上,(2^30 / 2^21) = 512 个线程将会用完虚拟内存(例如,x86 上通常附带的 Linux)。你可以通过为每个线程提供更小的堆栈来解决此问题,但由于大多数线程库不允许在创建线程后增加线程堆栈,因此这样做意味着将程序设计为最小化使用堆栈。不过,你还可以通过迁移到 64 位处理器来解决此问题。
Linux、FreeBSD 和 Solaris 中的线程支持正在改进,即使对于主流用户来说,64 位处理器也指日可待。也许在不久的将来,那些喜欢为每个客户端使用一个线程的人将能够使用这种范例,即使是 10000 个客户端。然而,目前如果你真的想支持那么多客户端,你可能最好使用其他一些范例。
有关毫不掩饰的支持线程的观点,请参阅由 von Behren、Condit 和 Brewer(UCB)在 HotOS IX 上发表的 《Why Events Are A Bad Idea(for High-concurrency Servers)》(《为什么事件是一个坏主意(关于高并发服务器)》)(49)。反线程阵营中有人愿意指出一篇反驳这一观点的论文吗?:-)
(49)《为什么事件是一个坏主意(关于高并发服务器)》:https://www.usenix.org/legacy/events/hotos03/tech/vonbehren.html
LinuxTheads
LinuxTheads 是 “标准 Linux 线程库” 的名称。它自从 glibc2.0 开始被集成到 glibc 中,并且大部分都兼容 Posix,但性能和信号支持不尽如人意 。
NGPT:适用于 Linux 的下一代 Posix 线程
NGPT 是 IBM 发起的一个项目,旨在为 Linux 带来良好的 Posix 兼容线程支持。它现在处于稳定的 2.2 版本,并且运行良好......但 NGPT 团队已经宣布,他们正在将 NGPT 代码库置于 “仅支持”模式,因为他们认为这是 “长期支持社区的最佳方式” 。NGPT 团队将继续致力于改进 Linux 线程支持,但现在专注于改进 NPTL。(感谢 NGPT 团队的出色工作以及他们向 NPTL 让步的优雅方式)
NPTL: 适用于 Linux 的原生 Posix 线程库
NPTL 是 Ulrich Drepper(glibc(50) 仁慈的 dict^H^H^H^Hmaintainer(51))和 Ingo Molnar 的一个项目,旨在为 Linux 带来世界一流的 Posix 线程支持。
(50)glibc:https://www.gnu.org/software/libc/
(51)dict^H^H^H^Hmaintainer:译者猜测是个网名
截至到2003年10月5日,NPTL 现在作为附加目录合并到 glibc cvs(52)树中(就像 linuxthreads 一样),因此几乎肯定会与 glibc 的下一个版本一起发布。
(52)cvs:译者注:一个版本控制工具,相似的有 SVN、GIT
第一个包含 NPTL 早期快照的主要发行版是 Red Hat 9。(这对一些用户来说有点不方便,但必须有人打破僵局......)
NPTL链接:
关于讨论NPTL的 mailing list(邮件列表)(https://listman.redhat.com/mailman/listinfo/phil-list)
NPTL 源代码(http://people.redhat.com/drepper/nptl/ 注:链接404)
NPTL的首次公告(https://lwn.net/Articles/10465/)
描述NPTL目标的原始白皮书(http://people.redhat.com/drepper/glibcthreads.html)
描述NPTL最终设计的修订白皮书(http://people.redhat.com/drepper/nptl-design.pdf)
Ingo Molnar 的第一个基准测试显示它可以处理 10^6 个线程(http://marc.theaimsgroup.com/?l=linux-kernel&m=103230439008204&w=2 注:打开页面空白)
Ulrich 的基准测试比较了 LinuxThreads、NPTL 和 IBM NGPT 的性能。这似乎表明 NPTL 比 NGPT 快得多。
这是我描述NPTL历史的尝试 (另见 Jerry Cooperstein 的文章):
2002年3月,NGPT 团队的 Bill Abt、glibc 维护人员 Ulrich Drepper 和其他人开会(53)讨论如何处理 LinuxThreads。会议提出的一个想法是提高互斥锁性能。Rusty Russell 等人随后实现了 快速用户空间互斥锁(futexes)(54),现在 NGPT 和 NPTL 都在使用这个互斥锁实现。大多数与会者认为 NGPT 应该合并到 glibc 中。
(53)会议信息:https://www.akkadia.org/drepper/glibcthreads.html
(54)futexes:http://marc.theaimsgroup.com/?l=linux-kernel&m=102196625921110&w=2 注:打开页面空白
然而,Ulrich Drepper 不喜欢 NGPT,并认为他可以做得更好。(对于那些曾经尝试过为 glibc 贡献补丁的人来说,这可能并不令人惊讶:-)在接下来的几个月里,Ulrich Drepper、Ingo Molnar 和其他人贡献了 glibc 和内核更改,这些更改构成了所谓的原生 Posix 线程库 (NPTL)。NPTL 使用为 NGPT 设计的所有内核增强功能,并利用了一些新的内核增强功能。Ingo Molnar 对内核增强功能的描述(55)如下:
(55)描述的链接:https://listman.redhat.com/pipermail/phil-list/2002-September/000013.html
虽然 NPTL 使用了 NGPT 引入的三个内核功能:getpid() 返回 PID、CLONE_THREAD 和 futexes,NPTL 还使用(并依赖)一个作为该项目的一部分开发的更广泛的新内核功能集。
NGPT 在2.5.8版本左右修改、清理和扩展了之前引入内核的一些项,例如线程组处理 (CLONE_THREAD)。(影响 NGPT 兼容性的 CLONE_THREAD 更改已与 NGPT 人员同步,以确保 NGPT 不会以任何不可接受的方式中断。)
为NPTL开发和使用的内核功能在设计白皮书中进行了描述,http://people.redhat.com/drepper/nptl-design.pdf...
简短列表:TLS 支持、各种克隆扩展(CLONE_SETTLS、CLONE_SETTID, CLONE_CLEARTID),POSIX 线程信号处理, sys_exit() 扩展(在 VM-release 时发布 TID futex),sys_exit_group() system-call、sys_execve() 增强功能和对分离线程的支持。
在扩展 PID 空间方面也进行了工作,例如:由于 64K PID 假设、max_pid和 pid 分配可扩展性工作导致的 procfs 崩溃。此外,还进行了许多仅针对性能的改进。
从本质上讲,这些新功能是 1:1 线程的不妥协的方法——内核现在在可以改进线程的所有方面都有帮助,我们精确地为每个基本线程原语执行最低限度的上下文切换和内核调用集。
两者之间的一大区别是 NPTL 是 1:1 线程模型,而 NGPT 是 M:N 线程模型(见下文)。尽管如此,Ulrich 的初始基准测试(56)似乎表明 NPTL 确实比 NGPT 快得多。(NGPT 团队正期待看到 Ulrich 的基准测试代码来验证结果)
(56)Ulrich 的初始基准测试:https://listman.redhat.com/pipermail/phil-list/2002-September/000009.html
FreeBSD 线程支持
FreeBSD 同时支持 LinuxThreads 和用户空间线程库。此外,FreeBSD 5.0 还引入了一个名为 KSE 的 M:N 实现。概览参阅:www.unobvious.com/bsd/freebsd-threads.html。
2003 年 3 月 25 日, Jeff Roberson 在 freebsd-arch 上发帖(57):
...感谢 Julian、David Xu、Mini、Dan Eischen 以及所有参与 KSE 和 libpthread 开发的人提供的基础,Mini 和我开发了一个 1:1 的线程实现。此代码与 KSE 并行工作,不会以任何方式破坏它。它实际上通过测试共享位(shared bits)来帮助拉近 M:N 线程的距离。...
2006 年 7 月,Robert Watson 提出 1:1 线程实现成为 FreeBsd 7.x 的默认实现(58):
(58)链接:http://marc.theaimsgroup.com/?l=freebsd-threads&m=115191979412894&w=2 注:打开页面空白
我知道这在过去已经讨论过了,但我认为随着 7.x 的蹒跚前行,是时候再考虑一下了。在许多常见应用程序和场景的基准测试中,libthr 明显表现出比 libpthread 更好的性能......libthr 也在我们更多的平台上实现,并且已经在几个平台上实现了 libpthread。我们向 MySQL 和其他重度线程用户提出的第一个建议是“切换到 libthr”,这也是有启发性的!...所以 strawman 的建议是:让 libthr 成为 7.x 上的默认线程库。
NetBSD 线程支持
根据 Noriyuki Soda 的说明:
内核支持的基于 Scheduler Activations(调度激活机制)模型的 M:N 线程库于 2003 年 1 月 18 日合并到 NetBSD-current 中。
有关详细信息,请参见 Wasabi Systems 公司的 Nathan J. Williams 在 FREENIX '02 上发表的 《An Implementation of Scheduler Activations on the NetBSD Operating System》(《在NetBSD操作系统上的一种调度激活机制实现》)。
Solaris 线程支持
Solaris 中的线程支持正在不断发展...从 Solaris 2 到 Solaris 8,默认线程库使用 M:N 模型,但 Solaris 9 默认为 1:1 模型线程支持。请参见《Sun 的多线程编程指南》和《Sun 关于 Java 和 Solaris 线程的说明》。
JDK 1.3.x 及更早版本中的 Java 线程支持
众所周知,JDK1.3.x 之前的 Java 不支持任何处理网络连接的方法,除了每个客户端一个线程。Volanomark 是一个很好的微基准测试,它以每秒消息为单位测量不同数量的同时连接的吞吐量。截至 2003 年 5 月,来自不同供应商的 JDK 1.3 实现实际上能够处理一万个并发连接,尽管性能会显著下降。请参阅表 4(59),了解哪些 JVM 可以处理 10000 个连接,以及性能如何随着连接数量的增加而受到影响。
(59)表 4:http://www.volano.com/report/#nettable 注:国内打不开,不知道是否还有效
注意:1:1 线程与 M:N 线程
在实现线程库时,有一个选择:你可以把所有的线程支持放在内核中(这称为 1:1 线程模型),也可以将相当多的线程支持移动到用户空间中(这称为 M:N 线程模型)。M:N 曾一度被认为是性能更高的,但它非常复杂,很难做到正确,大多数人都在远离它。
为什么 Ingo Molnar 更喜欢 1:1 而不是 M:N(http://marc.theaimsgroup.com/?l=linux-kernel&m=103284879216107&w=2 注:国内打不开,不知道是否还有效)
SUN 正在转向 1:1 线程
NGPT 是 Linux 的 M:N 线程库(注:链接已无效)
虽然 Ulrich Drepper 计划在新的 glibc 线程库中使用 M:N 线程, 但是他开始改用 1:1 线程模型
MacOSX 似乎使用 1:1 线程(http://developer.apple.com/technotes/tn/tn2028.html#MacOSXThreading)
FreeBSD 和 NetBSD 似乎仍然相信 M:N 线程......孤独的坚守者? 看起来 freebsd 7.0 可能会切换到 1:1 线程(见上文),所以也许 M:N 线程的信徒最终在任何地方都被证明是错误的(http://people.freebsd.org/~julian/)(http://web.mit.edu/nathanw/www/usenix/freenix-sa/ 注:链接访问access deny)
5. 将服务器代码构建到内核中
据说 Novell 和 Microsoft 都在不同的时期这样做过,至少有一个NFS实现是这样做,khttpd(60) 为Linux 和静态网页也这样做,而 “TUX”(线程linux网络服务器)是由 Ingo Molnar 为Linux 提供的令人眼花缭乱的快速和灵活的内核空间 HTTP 服务器。Ingo 在 2000 年 9 月 1 日的公告(61)中说,可以从 ftp://ftp.redhat.com/pub/redhat/tux 下载一个 alpha 版本的 TUX,并解释了如何加入邮件列表以获取更多信息。
(60)khttpd:http://www.fenrus.demon.nl/ 注:国内打不开,不知道是否还有效
(61)公告链接:http://marc.theaimsgroup.com/?l=linux-kernel&m=98098648011183&w=2 注:打开页面空白
linux-kernel mailing list 一直在讨论这种方法的利弊,共识似乎是内核应该添加尽可能小的钩子以提高 Web 服务器性能,而不是将 Web 服务器移动到内核中。这样,其他类型的服务器就可以受益。例如,参见 Zach Brown 关于用户空间与内核 http 服务器的评论(62)。看起来 2.4 linux 内核为用户程序提供了足够的功能,因为 X15 服务器的运行速度与 Tux 一样快,但没有使用任何内核修改。
(62)评论链接:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9906_03/msg01041.html 注:国内打不开,不知道是否还有效
将 TCP 堆栈引入用户空间
例如,参见网络映射数据包 I/O 框架(63),以及基于它的 Sandstorm 概念验证 Web 服务器(64)。
(63)网络映射数据包 I/O 框架:http://info.iet.unipi.it/~luigi/netmap/
(64)Sandstorm 概念验证 Web 服务器:http://conferences.sigcomm.org/hotnets/2013/papers/hotnets-final43.pdf
评论
Richard Gooch 写了一篇讨论 I/O 选项的论文(65)。
(65)论文链接:http://www.atnf.csiro.au/~rgooch/linux/docs/io-events.html 注:页面不存在了
2001 年,Tim Brecht 和 MMichal Ostrowski 测量了基于选择的简单服务器的各种策略的性能(66)。他们的数据值得一看。
(66)测试报告链接:http://www.hpl.hp.com/techreports/2001/HPL-2001-314.html 注:国内打不开,不知道是否还有效
2003 年,Tim Brecht 发布了 userver 的源代码,这是一个由 Abhishek Chandra、David Mosberger、David Pariag 和 Michal Ostrowski 编写的由多个服务器组合而成的小型 Web 服务器。它可以使用 select() 、poll() 、epoll() 或 sigio。
早在 1999 年 3 月,Dean Gaudet 就发帖(67)说:
(67)帖子链接:http://marc.theaimsgroup.com/?l=apache-httpd-dev&m=92100977123493&w=2 注:打开页面空白
我经常被问到:“你们为什么不使用像 Zeus 这样的基于 select/event 的模型?这显然是最快的。” ...
他的理由归结为:“这真的很难,而且回报尚不清楚”。 然而,在几个月内,很明显人们愿意为此而努力。
Mark Russinovich 写了一篇社论和一篇文章(68),讨论了 2.2 Linux 内核中的 I/O 策略问题。值得一读,即使他似乎在某些方面被误导了。特别是,他似乎认为 Linux 2.2 的异步 I/O(见上面的 F_SETSIG)不会在数据准备就绪时通知用户进程,而只会在新连接到达时通知用户进程。这似乎是一个奇怪的误会。另请参阅对早期草稿的评论(69),Ingo Molnar 1999 年 4 月 30 日的反驳(70),Russinovich 1999 年 5 月 2 日的评论(71),Alan Cox 的反驳(72),以及 linux-kernel 的各种帖子(73)。我怀疑他是想说 Linux 不支持异步磁盘 I/O,这曾经是真的,但现在 SGI 已经实现了 KAIO,它不再是真的了。
(68)文章链接:http://www.winntmag.com/Articles/Index.cfm?ArticleID=5048 注:国内打不开,不知道是否还有效
(69)对早期草稿的评论:http://www.dejanews.com/getdoc.xp?AN=431444525 注:国内打不开,不知道是否还有效
(70)反驳:http://www.dejanews.com/getdoc.xp?AN=472893693 注:国内打不开,不知道是否还有效
(71)评论:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9905_01/msg00089.html 注:国内打不开,不知道是否还有效
(72)Alan Cox的反驳:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9905_01/msg00263.html 注:国内打不开,不知道是否还有效
(73)linux-kernel 的各种帖子:http://www.dejanews.com/dnquery.xp?ST=PS&QRY=threads&DBS=1&format=threaded&showsort=score&maxhits=100&LNG=ALL&groups=fa.linux.kernel+&fromdate=jun+1+1998 注:国内打不开,不知道是否还有效
有关“completion ports(完成端口)”的信息,请参阅 sysinternals.com 和MSDN上的这些页面,他说这是NT独有的。简而言之,win32 的 “重叠 I/O” 被证明太低级了,不方便,而“completion ports(完成端口)”是一个包装器,它提供了一个完成事件队列,加上调度魔术——如果从这个端口拾取完成事件的其他线程正在休眠(也许是正在阻塞 I/O),它试图通过允许更多线程拾取完成事件来保持正在运行的线程数量不变。
另请参阅 OS/400 对 I/O 完成端口的支持(http://www.as400.ibm.com/developer/v4r5/api.html 注:文章找不到了)。
1999 年 9 月,在 linux-kernel 上进行了一次有趣的讨论,标题为 “> 15,000 个同时连接” (以及线程的第二周)。 要点:
Ed Hall 发布了一些关于他的经历的笔记(74),他在运行 Solaris 的 UP P2/333 上实现了 >1000 次连接/秒。他的代码使用了少量的线程(每个 CPU 1 或 2 个),每个线程使用“基于事件的模型”管理大量客户端。
(74)笔记链接:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9909_01/msg00807.html 注:国内打不开,不知道是否还有效
Mike Jagdis 发布了一篇关于 poll/select 开销的分析(75),他说:“当前的 select/poll 实现可以得到显着改进,尤其是在阻塞的情况下,但开销仍然会随着文件描述符数量的增加而增加,因为 select/poll 不会,也不能记住哪些描述符是感兴趣的。使用新的 API 很容易修复。欢迎提出建议...”
(75)分析文章:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9909_01/msg00831.html 注:国内打不开,不知道是否还有效
Mike 发布了他在改进 select() 和 poll() 方面的工作的文章(76)。
(76)文章链接:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9909_01/msg00964.html 注:国内打不开,不知道是否还有效
Mike发布了关于替换 poll() /select() 的一些可能的API的文章(77):“一个 '类似设备' 的API怎么样,API里编写 '类似pollfd' 的结构,'设备' 监听事件,并在你读取时传递 '类似pollfd' 的结构?..."
(77)文章链接:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9909_01/msg00971.html 注:国内打不开,不知道是否还有效
Rogier Wolff 建议(78)使用 “digital guys 建议的API”,http://www.cs.rice.edu/~gaurav/papers/usenix99.ps
(78)建议的链接:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9909_01/msg00979.html 注:国内打不开,不知道是否还有效
Joerg Pommnitz 指出(79),任何新的 API 都应该能够等待,不仅要等待文件描述符事件,还要等待信号,也许还要等待 SYSV-IPC。我们的同步原语当然应该至少能够执行 Win32 的 WaitForMultipleObjects 可以执行的操作。
(79)文章链接:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9909_02/msg00001.html 注:国内打不开,不知道是否还有效
Stephen Tweedie 断言(80),F_SETSIG、排队实时信号和 sigwaitinfo() 的组合是 http://www.cs.rice.edu/~gaurav/papers/usenix99.ps 年提出的 API 的超集。他还提到,如果你对性能感兴趣,你可以一直保持信号被阻塞,信号不会被异步传递,进程会使用 sigwaitinfo() 从队列中获取下一个信号。
(80)断言链接:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9909_02/msg01198.html 注:国内打不开,不知道是否还有效
Jayson Nordwick 将 completion ports(完成端口)与 F_SETSIG 同步事件模型进行了比较(81), 并得出结论——它们非常相似。
(81)比较的内容:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9909_03/msg00002.html 注:国内打不开,不知道是否还有效
Alan Cox 指出(82),SCT 的 SIGIO 补丁的旧版本包含在 2.3.18ac 中。
(82)原文:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9909_03/msg00043.html 注:国内打不开,不知道是否还有效
Jordan Mendelson 发布了一些示例代码(83),展示了如何使用 F_SETSIG。
(83)原文:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9909_03/msg00093.html 注:国内打不开,不知道是否还有效
Stephen C. Tweedie 继续比较completion ports(完成端口)和F_SETSIG(84),并指出:“使用信号出列机制的话,如果库使用相同的机制,您的应用程序将获得发往各种库组件的信号”,但库可以设置自己的信号处理程序,因此这应该不会对程序产生太大影响。
(84)原文:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9909_03/msg00095.html 注:国内打不开,不知道是否还有效
Doug Royer 指出(85),当他在 Sun 日历服务器上工作时,他在 Solaris 2.6 上获得了 100,000 个连接。其他人则附和了在Linux上需要多少RAM的估计,以及会遇到哪些瓶颈。
(85)原文:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9909_04/msg00900.html 注:国内打不开,不知道是否还有效
有趣的阅读!
对打开的文件句柄的限制
任意的Unix:通过 ulimit 或 setrlimit 的设置来限制。
Solaris:请参见 Solaris 常见问题解答, 问题 3.46(或在这个附近,他们会定期重新编号问题)。
FreeBSD:
编辑 /boot/loader.conf, 添加一行set kern.maxfiles=XXXX
其中 XXXX 是文件描述符所需的系统限制,然后重新启动。感谢一位匿名读者, 他写信说他在 FreeBSD 4.3 上实现了远远超过 10000 个连接, 并说
“FWIW:实际上,你不能通过 sysctl 来轻松调整 FreeBSD 中的最大连接数。你必须在 /boot/loader.conf 文件中执行此操作。
这样做的原因是 zalloci() 调用初始化 socket 和 tcpcb 结构区域在系统启动的非常早期发生,以便区域既类型稳定又可交换。
你还需要将 mbuf 的数量设置得更高,因为你将(在未修改的内核上)为 tcptempl 结构的每个连接消耗一个 mbuf,这些结构用于实现 keepalive。”
另一位读者说
“从 FreeBSD 4.4 开始,不再分配 tcptempl 结构,你不再需要担心每个连接会消耗一个 mbuf。”
另请参阅:
FreeBSD 使用手册(http://www.freebsd.org/doc/en_US.ISO8859-1/books/handbook/configtuning-kernel-limits.html 注:国内打不开,不知道是否还有效)
“man tuning”中的 SYSCTL TUNING(86)、LOADER TUNABLES(87) 和 KERNEL CONFIG TUNING(88)
(86)SYSCTL TUNING:http://www.freebsd.org/cgi/man.cgi?query=tuning#SYSCTL+TUNING
(87)LOADER TUNABLES:http://www.freebsd.org/cgi/man.cgi?query=tuning#LOADER+TUNABLES
(88)KERNEL CONFIG TUNING:http://www.freebsd.org/cgi/man.cgi?query=tuning#KERNEL+CONFIG+TUNING
The Effects of Tuning a FreeBSD 4.3 Box for High Performance(《调整 FreeBSD 4.3 机器以实现高性能的效果》), Daemon News, 2001 年 8 月(http://www.daemonnews.org/200108/benchmark.html 注:国内打不开,不知道是否还有效)
postfix.org 调整说明, 涵盖 FreeBSD 4.2 和 4.4(http://www.postfix.org/faq.html#moby-freebsd 注:国内打不开,不知道是否还有效)
Measurement Factory 的笔记,大约在 FreeBSD 4.3。
OpenBSD: 一位读者说
“在 OpenBSD 中,需要进行额外的调整来增加每个进程可用的打开文件句柄的数量:需要增加 /etc/login.conf(89)中的 openfiles-cur 参数。你可以使用 sysctl -w 或在 sysctl.conf 中更改 kern.maxfiles,但它不起作用。这很重要,因为在发布时,login.conf 限制对于非特权进程来说是相当低的64,对于特权进程来说是128。”
(89)/etc/login.conf:http://www.freebsd.org/cgi/man.cgi?query=login.conf&manpath=OpenBSD+3.1
Linux:请参阅 Bodo Bauer 的 /proc 文档(90)。
(90)/proc文档:http://asc.di.fct.unl.pt/~jml/mirror/Proc/ 注:国内打不开,不知道是否还有效
在 2.4 内核上:
echo 32768 > /proc/sys/fs/file-max
增加打开文件的系统限制值,并
ulimit -n 32768
增加当前进程的限制值。
在 2.2.x 内核上:
echo 32768 > /proc/sys/fs/file-max
echo 65536 > /proc/sys/fs/inode-max
增加打开文件的系统限制值,并
ulimit -n 32768
增加当前进程的限制值。
我验证了 Red Hat 6.0(2.2.5 左右加上补丁)上的进程可以以这种方式打开至少 31000 个文件描述符。另一位研究员已经验证了 2.2.12 上的进程可以以这种方式打开至少 90000 个文件描述符(有适当的限制)。上限似乎是可用内存。
Stephen C. Tweedie 发布了关于如何使用 initscript 和 pam_limit 在启动时对全局或每个用户设置 ulimit 限制的文章(91)。
(91)文章链接:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9909_02/msg01092.html 注:国内打不开,不知道是否还有效
但是,在较旧的 2.2 内核中,即使进行了上述更改,每个进程的打开文件数仍限制为 1024 个。
另请参阅 Oskar 在 1998 年发表的文章(92),其中讨论了 2.0.36 内核中文件描述符的每个进程和系统范围的限制。
(92)文章链接:http://www.dejanews.com/getdoc.xp?AN=313316592 注:国内打不开,不知道是否还有效
线程限制
在任何体系结构上,都可能需要减少为每个线程分配的堆栈空间量,以避免耗尽虚拟内存。如果您使用的是 pthreads,则可以在运行时使用 pthread_attr_init() 进行设置。
Solaris:据我所知,它支持内存中可以容纳的尽可能多的线程。
带有 NPTL 的 Linux 2.6 内核:/proc/sys/vm/max_map_count 可能需要增加到 32000 个左右的线程数。(不过,除非您使用的是 64 位处理器,否则您需要使用非常小的堆栈线程才能接近该数量的线程)有关更多信息,请参阅 NPTL 邮件列表,例如线程相关的主题为 “无法创建超过 32K 个线程?”。
Linux 2.4:/proc/sys/kernel/threads-max 是最大线程数。在我的 Red Hat 8 系统上,它默认为 2047。您可以像往常一样通过将新值echo到该文件中来设置增加它,例如“echo 4000 > /proc/sys/kernel/threads-max”
Linux 2.2:即使是 2.2.13 内核也限制了线程数,至少在 Intel 上是这样。我不知道其他架构的限制是什么。Mingo 在 Intel 上发布了 2.1.131 的补丁(93),删除了此限制。它似乎已集成到 2.3.20 中。
(93)补丁:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9812_02/msg00048.html 注:国内打不开,不知道是否还有效
另请参阅 Volano 关于在 2.2 内核中提高文件、线程和 FD_SET 限制的详细说明(94)。哇。本文档将引导你完成许多自己很难弄清楚但有些过时的内容。
(94)详细说明:http://www.volano.com/linux.html 注:国内打不开,不知道是否还有效
Java:阅读Volano 的详细基准测试信息(95),以及他们关于如何调整各种系统以处理大量线程的信息(96)。
(95)Volano 的详细基准测试信息:http://www.volano.com/benchmarks.html 注:国内打不开,不知道是否还有效
(96)关于如何调整各种系统以处理大量线程的信息:http://www.volano.com/server.html 注:国内打不开,不知道是否还有效
Java 问题
在 JDK 1.3 之前,Java 的标准网络库主要提供 每个客户端一个线程 的模型。有一种方法可以进行非阻塞读取,但没有方法可以进行非阻塞写入。
2001 年 5 月,JDK 1.4 引入了 java.nio 包,以提供对非阻塞 I/O(以及其他一些好东西)的完全支持。有关一些注意事项,请参阅发行说明。尝试一下并给予 SUN 反馈!
HP 的 java 还包括一个 Thread Polling API(线程轮询API)。
2000 年,Matt Welsh 为 Java 实现了非阻塞socket。他的性能基准测试表明,与在处理许多(最多 10000 个)连接的服务器中阻塞套接字相比,它们具有优势。他的类库称为 java-nbio;它是 Sandstorm 项目的一部分。基准测试显示 10000 个连接的性能是可行的。
另请参阅 Dean Gaudet 关于 Java、网络 I/O 和线程的文章(97),以及 Matt Welsh 关于 事件vs工作线程 的论文。
(97)文章:http://arctic.org/~dean/hybrid-jvm.txt
在NIO之前,有几个改进 Java 网络 API 的建议:
Matt Welsh 的 Jaguar 系统提出了预序列化对象、新的 Java 字节码和内存管理更改,以允许在 Java 中使用异步 I/O。
将 Java 连接到虚拟接口架构(98),由 C-C. Chang 和 T. von Eicken 提出了内存管理更改,以允许在 Java 中使用异步 I/O。
(98)将 Java 连接到虚拟接口架构:http://www.cs.cornell.edu/Info/People/chichao/papers.htm
JSR-51 是 Sun 项目,它提供了 java.nio 包。Matt Welsh 参与了其中(谁说 Sun 不听?)
其他技巧
Zero-Copy(零拷贝)
通常,数据在从这里到那里的途中会被复制很多次。任何将这些副本消除到最低物理值的方案都称为 “zero-copy(零拷贝)” 。
Thomas Ogrisegg 在 Linux 2.4.17-2.4.20 下为 mmaped files(内存映射文件) 提供的 zero-copy发送补丁(99)。声称它比 sendfile() 快。
(99)zero-copy发送补丁:http://marc.theaimsgroup.com/?l=linux-kernel&m=104121076420067&w=2 注:页面空白
IO-Lite(100) 是一组 I/O 原语的提案,它消除了对许多副本的需求(即减少了拷贝)。
(100)IO-Lite:http://www.usenix.org/publications/library/proceedings/osdi99/full_papers/pai/pai_html/pai.html
Alan Cox 指出,回到 1999 年,zero-copy 有时不值得麻烦(101)。(不过,他确实喜欢 sendfile())
(101)文章:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9905_01/msg00263.html 注:国内打不开,不知道是否还有效
Ingo 在 2000 年 7 月的 TUX 1.0 的 2.4 内核中已实现一种 zero-copy TCP 的形式(102),并表示他将很快将其在用户空间上可用。
(102)文章:http://boudicca.tux.org/hypermail/linux-kernel/2000week36/0979.html 注:国内打不开,不知道是否还有效
Drew Gallatin 和 Robert Picco 为 FreeBSD 添加了一些 zero-copy 特性(103)。这个想法似乎是,如果你在 socket 上调用 write() 或 read() ,指针是 page-aligned(页对齐)的,并且传输的数据量至少是一页,*并且*你不会立即重用这个缓冲区,内存管理技巧将被用于避免复制。但是,请参阅 linux-kernel 上此消息的后续内容(104),了解人们对这些内存管理技巧的速度的担忧。
(103)文章:http://people.freebsd.org/~ken/zero_copy/
(104)后续:http://boudicca.tux.org/hypermail/linux-kernel/2000week39/0249.html 注:国内打不开,不知道是否还有效
根据 Noriyuki Soda 的说明:
“从 NetBSD-1.6 release 版本开始,通过指定 “SOSEND_LOAN” 内核选项来支持发送端 zero-copy。这个选项现在是 NetBSD-current 的默认选项(您可以通过在 NetBSD_current 的内核选项中指定 “SOSEND_NO_LOAN” 来禁用此功能)。使用此功能,如果将超过 4096 字节的数据被指定为要发送的数据,则会自动启用 zero-copy。”
sendfile() 系统调用可以实现 zero-copy 网络。
Linux 和 FreeBSD 中的 sendfile() 函数允许你告诉内核发送部分或全部文件。这使操作系统可以尽可能高效地执行此操作。它同样可以在使用线程的服务器或使用非阻塞 I/O 的服务器中使用。(在 Linux 中,它目前记录得很差,用 _syscall4 来调用它(105)。Andi Kleen 正在编写新的手册页来介绍这一点。另请参阅 Jeff Tranter 在 Linux Gazette 第 91 期中撰写的《Exploring The sendfile System Call》(《探索sendfile的系统调用》)。有传言说(106),ftp.cdrom.com 从 sendfile() 中明显受益。
(105)文档:http://www.dejanews.com/getdoc.xp?AN=422899634 注:国内打不开,不知道是否还有效
(106)链接:http://www.dejanews.com/getdoc.xp?AN=423005088 注:国内打不开,不知道是否还有效
一个 sendfile() 的 zero-copy实现 即将用于 2.4 内核。 请参阅 LWN,2001年1月25日(107)。
(107)LWN:http://lwn.net/2001/0125/kernel.php3
一个在 FreeBSD 中使用 sendfile() 的开发人员报告说,使用 POLLWRBAND 而不是 POLLOUT 有很大的不同。
Solaris 8(自从 2001 年 7 月更新)具有一个 “sendfilev” 的新系统调用。此处提供了手册页的副本(108)。Solaris 8 7/01 发行说明也提到了它。我怀疑这个新系统调用在以阻塞模式发送到 socket 时最有用,与非阻塞 socket 一起使用会有点痛苦。
(108)手册页副本:http://www.kegel.com/sendfilev.txt
通过使用 writev(或 TCP_CORK)来避免使用小帧
TCP_CORK,Linux 下的一个新 socket 选项告诉内核避免发送部分帧,这有点帮助,例如,由于某种原因你不能把很多小的 write() 调用捆绑在一起。取消设置该选项将刷新缓冲区。不过,最好使用 writev() ...
参见 LWN 2001 年 1 月 25 日(109),了解 linux-kernel 上关于 TCP_CORK 和可能的替代——MSG_MORE 的一些非常有趣的讨论的摘要。
(109)LWN :http://lwn.net/2001/0125/kernel.php3
在过载时行为明智。
[Provos、Lever 和 Tweedie 2000](110)指出,当服务器过载时丢弃到来的连接可以改善性能曲线的形状,并降低总体错误率。他们使用一个平滑版本的 “具有 I/O 就绪的客户端数量” 作为过载的度量。这种技术应该很容易地适用于使用 select、poll 或任何每次调用返回就绪事件计数的系统调用(例如 /dev/poll 或 sigtimedwait4() )编写的服务器。(110)下载链接:http://www.citi.umich.edu/techreports/reports/citi-tr-00-7.ps.gz
一些程序可以从使用非 Posix 线程中受益。
并非所有线程都是平等创建的。例如,Linux 中的 clone() 函数(以及它在其他操作系统中的类似函数)允许您创建一个具有自己当前工作目录的线程,这在实现一个 ftp 服务器时非常有用。有关使用 native threads 而不是 pthread 的示例,请参阅 Hoser FTPd。
缓存自己的数据有时可能是一种胜利。
5 月 9 日,Vivek Sadananda Pai (vivek@cs.rice.edu) 在 new-httpd 上发表的 《Re: fix for hybrid server problems》(111) 指出:
(111) 文章链接:http://www.humanfactor.com/cgi-bin/cgi-delegate/apache-ML/nh/1999/ 注:国内打不开,不知道是否还有效
“我在 FreeBSD 和 Solaris/x86 上比较了基于选择的服务器和多进程服务器的原始性能。在 microbenchmarks 中,软件架构在性能上只有细微的差异。基于选择的服务器在性能方面的巨大优势源于执行应用程序级别的缓存。虽然多进程服务器可以以更高的成本做到这一点,但在实际工作负载(与microbenchmarks相比)上很难获得相同的好处。我将把这些测量结果作为论文的一部分进行展示,该论文将出现在下一届Usenix会议上。如果你有补充,可以在 http://www.cs.rice.edu/~vivek/flash99/ 上获得论文”
其他限制
老的系统库可能使用16 bit 的变量来保存文件句柄,这会在 32767 个句柄以上时产生问题。glibc2.1 应该没问题。
许多系统使用 16 bit 的变量来保存进程或线程 ID。将 Volano 可伸缩性基准测试(112)移植到 C 语言,看看各种操作系统的线程数上限是多少,将会很有趣。
(112)Volano 可伸缩性基准测试:http://www.volano.com/benchmarks.html 注:国内打不开,不知道是否还有效
某些操作系统预分配了过多的本地线程内存,如果每个线程获得 1MB,并且总的虚拟内存空间为 2GB,则上限为创建 2000 个线程。
查看 http://www.acme.com/software/thttpd/benchmarks.html 底部的性能比较图。注意到各种服务器在128个连接以上出现问题,即使在 Solaris 2.6 上也是如此?任何弄清楚原因的人,请告诉我答案。
注意:如果 TCP 堆栈有一个bug,导致在 SYN 或 FIN 时间出现短时间(200 毫秒)延迟,就像 Linux 2.2.0-2.2.6 一样,OS 或 http守护进程 拥有一个对打开的连接数有硬性的限制,你完全可以预期这种行为。不过可能是其他原因。
内核问题
对于 Linux,内核瓶颈似乎正在不断j被解决。 参见 Linux每周新闻(LWN)(113),Kernel Traffic(114),Linux-Kernel mailing list(115),和我的 Mindcraft Redux 页面(116)。
(113)LWN:http://lwn.net/
(114)Kernel Traffic:http://www.kt.opensrc.org/ 注:国内打不开,不知道是否还有效
(115)Linux-Kernel mailing list:http://marc.theaimsgroup.com/?l=linux-kernel 注:页面空白
(116)Mindcraft Redux 页面:http://www.kegel.com/mindcraft_redux.html
1999 年 3 月,Microsoft 赞助了一个基准测试,将 NT 与 Linux 在为大量 http 和 smb 客户端提供服务时进行比较,其中他们未能从 Linux 中看到良好的结果。有关更多信息,请参阅我关于 Mindcraft 1999 年 4 月基准测试的文章(117)。
(117)文章链接:http://www.kegel.com/mindcraft_redux.html
另请参阅 Linux 可伸缩性项目(118)。 他们正在做一些有趣的工作,包括 Niels Provos 的 hinting poll 补丁(119),以及一些关于 thundering herd 问题(120)的工作。
(118)Linux 可伸缩性项目:http://www.citi.umich.edu/projects/citi-netscape/
(119)hinting poll 补丁:http://linuxwww.db.erau.edu/mail_archives/linux-kernel/May_99/4105.html 注:国内打不开,不知道是否还有效
(120)thundering herd 问题:http://www.citi.umich.edu/projects/linux-scalability/reports/accept.html
另请参阅Mike Jagdis 在改进 select() 和 poll() 方面的工作(121),这是 Mike 关于它的帖子(122)。
(121)文章:http://www.purplet.demon.co.uk/linux/select/ 注:国内打不开,不知道是否还有效
(122)帖子:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9909_01/msg00964.html 注:国内打不开,不知道是否还有效
Mohit Aron(aron@cs.rice.edu)写道,TCP 中基于速率的时钟可以将“慢速”连接的 HTTP 响应时间缩短 80%(123)。
(123)文章:http://www.linuxhq.com/lnxlists/linux-kernel/lk_9910_02/msg00889.html 注:国内打不开,不知道是否还有效
测量服务器性能
特别是两个测试是简单、有趣和困难的:
每秒原始连接数(每秒可以处理多少个 512 字节的文件?)
具有许多慢客户端的大型文件的总传输速率 (在性能开始下降之前,有多少个 28.8K Modem客户端可以同时从你的服务器下载?)
Jef Poskanzer 发布了比较许多 Web 服务器的基准测试。 请参阅 http://www.acme.com/software/thttpd/benchmarks.html 了解他的结果。
我还有一些关于将 thttpd 与 Apache 进行比较的旧笔记,初学者可能会感兴趣。
Chuck Lever 不断提醒我们(124)关于 Banga 和 Druschel 在 Web 服务器上进行基准测试的论文。值得一读。
(124)来源帖子:http://linuxhq.com/lnxlists/linux-kernel/lk_9906_02/msg00248.html 注:国内打不开,不知道是否还有效
IBM 有一篇优秀的论文,标题为 Java 服务器基准测试(125) [Baylor等人,2000]。值得一读。
(125)论文链接:http://www.research.ibm.com/journal/sj/391/baylor.html
例子
Nginx(126)是一个 Web 服务器,它使用目标操作系统上可用的任何高效网络事件机制。它越来越受欢迎,甚至还有关于它的书(127)(自从最初写成的这一版以来,还有更多,包括该书的第四版(128))。
(126)nginx官网:http://nginx.org/
(127)书籍购买链接:http://www.amazon.com/Nginx-HTTP-Server-Cl%C3%A9ment-Nedelcu/dp/1849510865/
(128)书籍购买链接:https://www.amazon.com/Nginx-HTTP-Server-Harness-infrastructure/dp/178862355X
有趣的基于 select() 的服务器
thttpd十分简单。使用的是单个进程。它具有良好的性能, 但不随 CPU 数量而扩展。也可以使用 kqueue。(thttpd:http://www.acme.com/software/thttpd/)
mathopd。类似于 thttpd。(mathopd:http://mathop.diva.nl/ 注:国内打不开,不知道是否还有效)
fhttpd(http://www.fhttpd.org/ 注:国内打不开,不知道是否还有效)
boa(http://www.boa.org/)
Roxen(注:原链接变成了出版印刷公司的官网)
Zeus,一个试图成为绝对最快的商业服务器。请参阅他们的调优指南。(注:原链接官网没了)
http://www.acme.com/software/thttpd/benchmarks.html 中列出的其他非 Java 服务器
BetaFTPd(注:原链接官网404)
Flash-Lite。使用 IO-Lite 的 Web 服务器。(注:原链接官网404)
Flash:一个高效且可移植的 Web 服务器 -- 使用 select() 、mmap() 、mincore() (注:原链接官网404)
截至 2003 年的 Flash Web 服务器 -- 使用 select() 、修改后的 sendfile() 和 async open() (注:原链接官网502)
xitami - 使用 select() 来实现自己的线程抽象,以便可移植到没有线程的系统。(http://www.imatix.com/html/xitami/ 注:国内打不开,不确定是否可用)
Medusa - Python 中的服务器编写工具包,试图提供非常高的性能。(http://www.nightmare.com/medusa/medusa.html 注:国内打不开,不确定是否可用)
userver - 可以使用 select、poll、epoll 或 sigio 的小型 HTTP 服务器(注:原链接官网404)
有趣的基于 /dev/poll 的服务器
N. Provos、C. Lever,“Linux 中的可扩展网络 I/O(129)”,2000 年 5 月。[FREENIX track, Proc. USENIX 2000,San Diego,California(2000年6月)] 描述一个修改为支持 /dev/poll 的 thttpd 版本。性能与 phhttpd 进行比较。
(129)Linux 中的可扩展网络 I/O:http://www.citi.umich.edu/techreports/reports/citi-tr-00-4.pdf
有趣的基于 epoll 的服务器
cmogstored - 将 epoll/kqueue 用于大多数网络,将线程用于磁盘和 accept4(http://bogomips.org/cmogstored/README)
有趣的基于 kqueue() 的服务器
thttpd(自 2.21 版本开始?)(thttpd:http://www.acme.com/software/thttpd/)
Adrian Chadd 说:“我正在做很多工作来让 squid 实际上像一个 kqueue IO 系统”;这是一个官方的 Squid 子项目;请参阅 http://squid.sourceforge.net/projects.html#commloops。(这显然比Benno(130) 的补丁(131)更新)
(130)Benno:http://www.advogato.org/person/benno/ 注:国内打不开,不确定是否可用
(131)补丁下载链接:http://netizen.com.au/~benno/squid-select.tar.gz
有趣的基于实时信号的服务器
Chromium的X15。 它使用 2.4 内核的 SIGIO 特性以及 sendfile() 和 TCP_CORK,据报道它的速度甚至比 TUX 还要高。源代码(132)在社区源代码(非开源)许可下可用。请参阅Fabio Riccardi 的原公告(133)。
(132)源代码获取:https://www.chromium.org/developers/how-tos/get-the-code/
(133)公告链接:http://boudicca.tux.org/hypermail/linux-kernel/2001week21/1624.html 注:国内打不开,不确定是否可用
Zach Brown 的 phhttpd(134) - “一个快速的 Web 服务器,用于展示 sigio/siginfo 事件模型。如果你尝试在生产环境中使用它,请考虑此代码是高度实验性的,并且你也精神正常”。 使用 2.3.21 或更高版本的 siginfo 功能,并包含早期内核所需的补丁。传闻比 khttpd 还要快。一些说明见他1999年5月31日的帖子(注:帖子页面已无)。
(134)phhttpd:http://www.zabbo.net/phhttpd/ 注:国内打不开,不确定是否可用
有趣的基于线程的服务器
Hoser FTPD(135)。 请参阅他们的基准测试页面(136)。
(135)Hoser FTPD:http://www.zabbo.net/hftpd/ 注:国内打不开,不确定是否可用
(136)基准测试页面:http://www.zabbo.net/hftpd/bench.html 注:国内打不开,不确定是否可用
Peter Eriksson 的 phttpd(注:原链接404)
Peter Eriksson 的 pftpdvv(注:原链接404)
http://www.acme.com/software/thttpd/benchmarks.html 中列出的基于 Java 的服务器
Sun 的 Java Web Server(137)(据报道,它可以同时处理 500 个客户端(138))
(137)Java Web Server:http://jserv.javasoft.com/ 注:国内打不开,不确定是否可用
(138)报道:http://archives.java.sun.com/cgi-bin/wa?A2=ind9901&L=jserv-interest&F=&S=&P=47739 注:国内打不开,不确定是否可用
有趣的 in-kernel 服务器
khttpd(http://www.fenrus.demon.nl/ 注:国内打不开,不确定是否可用)
“TUX”(Threaded linUX 网络服务器)(注:原链接失效),由 Ingo Molnar 等人提供,适用于 2.4 内核。
其他有趣的链接
Jeff Darcy 关于高性能服务器设计的笔记(注:原链接失效)
Ericsson 的 ARIES 项目 -- 在 1 到 12 个处理器上,Apache 1 vs. Apache 2 vs. Tomcat 的基准测试结果 (http://www2.linuxjournal.com/lj-issues/issue91/4752.html 注:国内打不开,不确定是否可用)
Peter Ladkin 教授的 Web 服务器性能页面。(http://nakula.rvs.uni-bielefeld.de/made/artikel/Web-Bench/web-bench.html 注:国内打不开,不确定是否可用)
Novell's 的 FastCache -- 声称每秒有 10000 次点击。相当漂亮的性能图表。(注:原链接404)
Rik van Riel 的 Linux 性能调优站点(http://linuxperf.nl.linux.org/ 注:国内打不开,不确定是否可用)
译后记
当你看到这里,大概会对这篇经典文章感觉有些困惑。
好像懂了很多东西,又好像多了很多不懂的东西。
这很正常,文章里面涉及了太多的很底层很细节的内容,何况还有一些东西因为年代久远都难以寻见真面容。
译者看来,这篇文章像是一个起点,可以顺着文中提及的如此多的观点、文章、方案,去摸索拼凑,最终一窥当年各位大佬思想碰撞的画面。